论文分享——Long Time No See! Open-Domain Conversation with Long-Term Persona Memory
大多数开放域对话模型在长期人机对话的环境中往往表现不佳。可能的原因是他们缺乏理解和记忆长期对话历史信息的能力。论文提出了一个新的长时记忆对话任务(LeMon),构建了一个新的对话数据集DuLeMon和一个具有长时记忆机制的对话生成框架PLATO-LTM。这种LTM机制使对话系统能够准确地提取和持续更新长期角色记忆,而不需要多会话对话数据集进行模型训练,从而提高对话的一致性和吸引力。论文的工作是第一次尝试对双方的角色信息进行实时动态管理,包括用户和聊天机器人。
Introduction
人物角色对于开放域对话系统与用户建立长期亲密关系至关重要,然而,目前的开放领域对话系统仍然无法与用户建立长期的联系。可能的原因是他们缺乏理解和记忆长期对话历史信息的能力,我们称之为长期角色记忆(Long-term persona ability)。记住并积极利用用户的角色信息可以增加对话的参与度,否则每当开启一个新对话时,聊天机器人又会表现得像是一个陌生人一样。
在开放域对话中利用长期人物角色信息缺乏任务设计和相应的数据集,大规模模型的长期角色记忆能力研究较少。现有的角色对话数据集例如PersonaChat只关注聊天机器人自身角色的一致性,而忽略了对用户角色信息的记忆和利用。他们都设置了固定的角色,不能在聊天期间更新。Xu等人提出了MSC数据集作为PersonaChat的多会话扩展,总结和回忆以前的对话以便将来生成对话,然而存储在MSC中的文档不会被动态修改,并且会随着会话的进行无限增加。此外,检索增强生成模型依赖于长会话会话数据集进行训练,成本消耗是巨大的。
为了解决现有模型的局限性和上述的问题,论文定义了LeMon(Long-term Memory Conversation)任务:在与用户的长期对话互动中,不断构建和更新对用户人物形象的认识和记忆。保持自身人物形象的一致性。在对话中主动利用已积累的双方人物形象信息,使对话更具参与感、内聚性和深度。并提出了一个名为DuLeMon的新数据集和一个具有长时记忆机制的对话生成框架PLATO-LTM,PLATO-LTM可以实时地从对话中提取双方的角色信息,分别将其写入角色记忆中,并从记忆中检索双方的角色信息以生成响应。
Related Work
Persona Dialogue
角色对话相关的工作一般分为隐式角色模型和显式角色模型,隐式角色模型是指将角色信息以语义角色向量的形式表示,基于检索的方法将人物角色和用户兴趣整合到对话系统中。缺点是在目标响应生成中不容易解释和控制。显式角色模型则提供一个明确的角色模型来为给定的角色信息生成一致的响应,机器的角色信息包括姓名、性别、爱好等。包含角色信息的聊天数据集有PersonaChat数据集、MSC数据集等,这些是目前最先进的长期对话包含角色注释的数据集
Dialogue Model with External Memory
基于规则的对话系统性能远落后于LLM,现有数据集上训练的LLM在长期对话上表现不佳,早期对话系统使用了各种记忆架构来从先前对话中提取、存储和利用相关信息。对每个用户分别记录和利用他们之间特有的交互记忆给系统的个性化和扩展带来了挑战。Campos等人介绍了一个代理使用其会话记忆来重新访问与用户共享的历史,以随着时间的推移保持连贯的社会关系。然而,他们发现利用与单个用户共享的历史记录具有挑战性,并且很难适应预期的会话协调模式。
DuLeMon Dataset
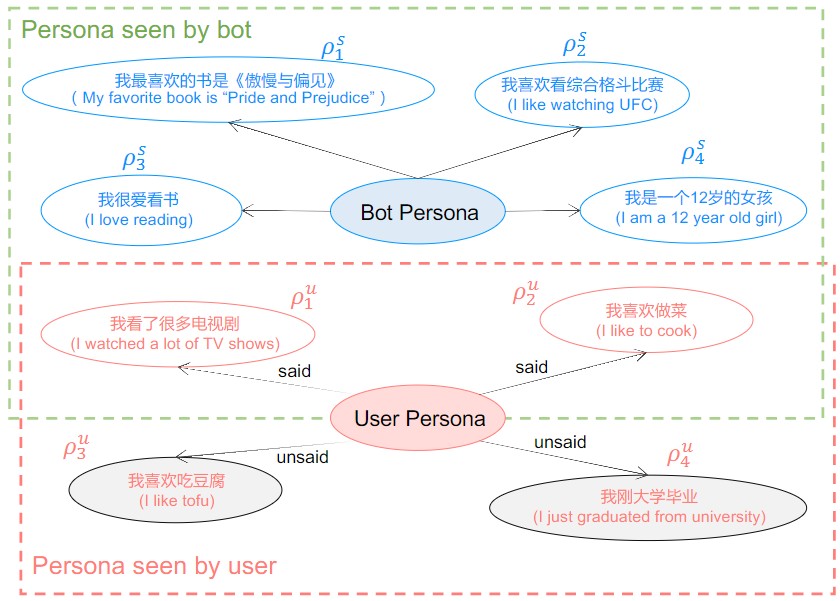
构建DuLeMon数据集的动机是降低长会话角色聊天数据集的收集成本,不依赖于高收集成本的长会话来研究角色聊天中的长期记忆问题,在任务设计和数据收集方面与最先进的长期角色对话数据集MSC有显著差异。给定任务:给定对话上下文c = {u_1,s_1,u_2,s_2,...,u_t−1,s_t−1,u_t},其中u和s分别代表用户和代理,给定用户和代理角色定义ρ^u = {ρ_1^u,ρ_2^u,...,ρ_m^u},ρ^s = {ρ_1^s,ρ_2^s,...,ρ_n^s},任务目标是找到对应的角色信息并预测聊天机器人的响应s_t。DuLeMon数据集的收集步骤如下:每个对话中需要两个工作人员分别扮演聊天机器人和用户,聊天机器人需要围绕已知用户角色和不断探索到的新角色信息来开展对话。如右图所示,Bot Persona是代理的角色信息,User Persona是用户的角色信息,其中用户的角色信息包含聊天机器人已知的角色信息和未知的角色信息。在对话进行中聊天机器人能够不断地获知新的用户角色信息,并进一步开展后续对话。

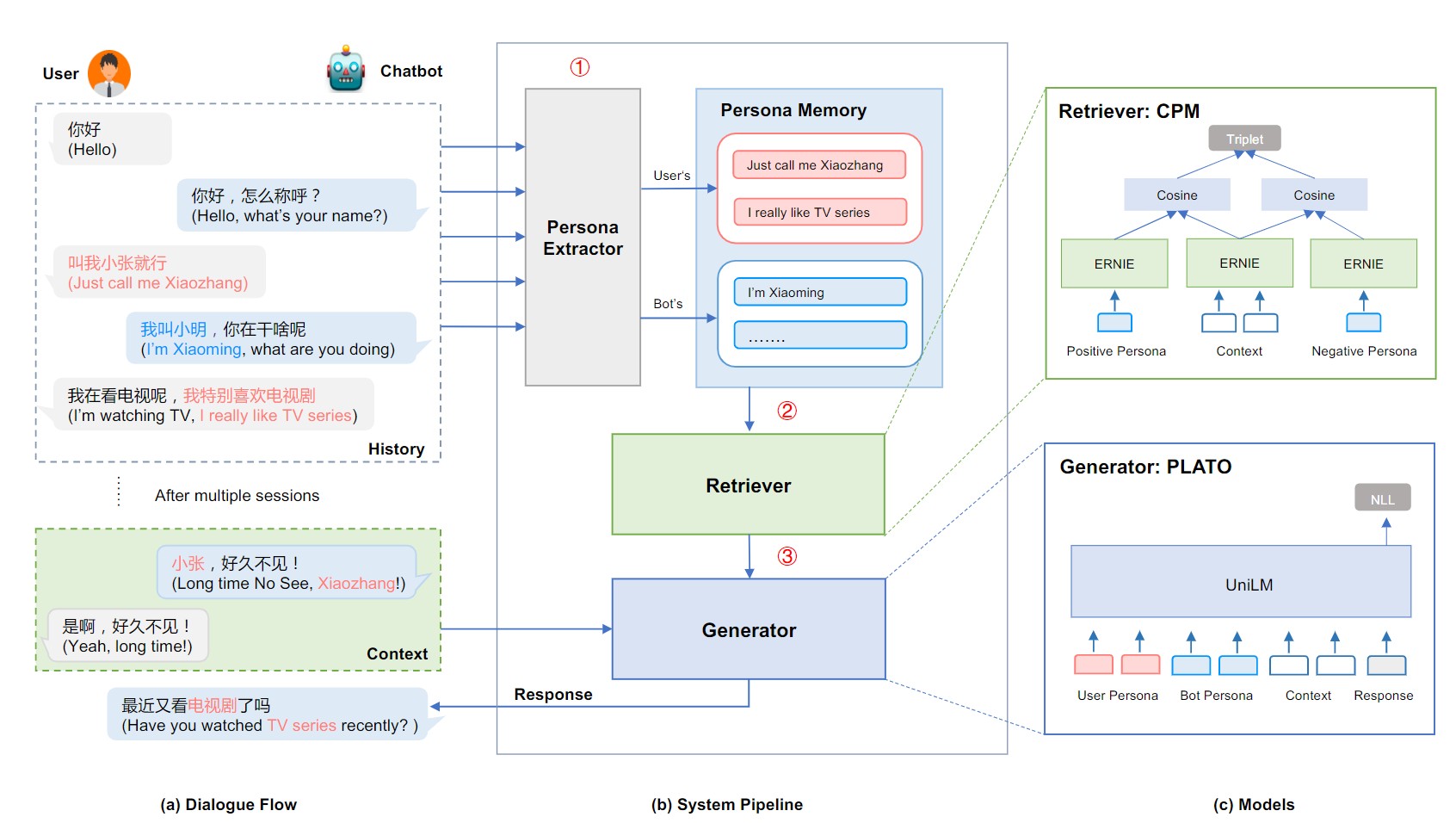
PLATO-LTM(基于显式记忆读写机制的长期记忆对话系统)
PLATO-LTM的架构如下图所示,包含三个模块:①角色提取器、②长期角色记忆和③响应生成模块
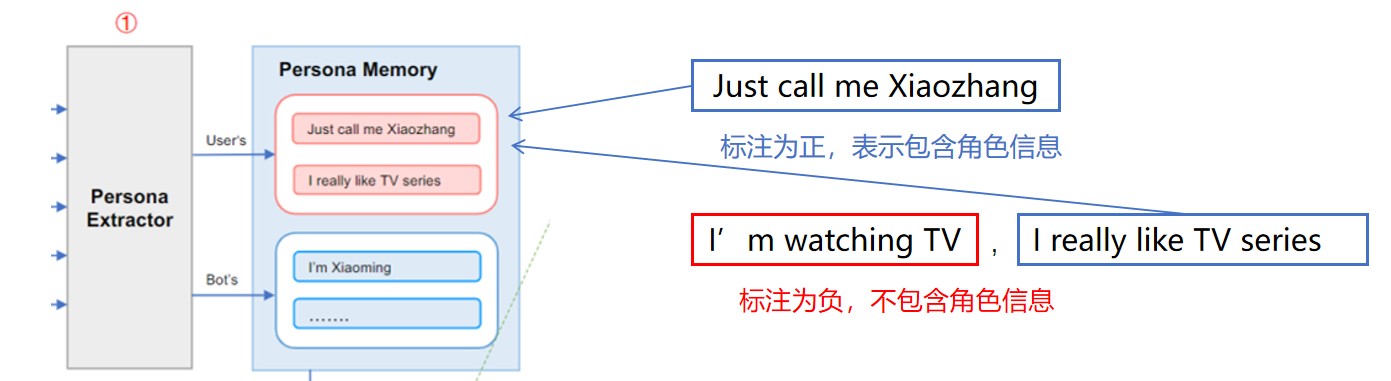
Persona Extractor(角色提取器)
角色提取器可以为每个文本输入分配一个标签来指示它是否包含角色信息,使用带注释的角色话语数据集来训练 ERNIE-CNN 网络架构,其中预训练的 ERNIE2 网络进行句子表示,CNN模型用于分类。训练步骤分为以下三步:
- 人工标注正标签(含角色信息)和负标签(不含)6k个话语(来自DuLeMon语料库和中文社交论坛语料库)训练5个不同参数的ERNIE-CNN网络(pc-stage1)
- 使用这五个网络模型自动标注140万条话语,对每个句子若五个至少两个模型将其标注为正,则为正,否则为负,得到一个细化后的带有是否包含角色信息标注的数据集
- 用Step2中的数据集来训练5个不同参数的模型,选性能最好的一个作为架构中的角色提取器(pc-stage2)
Long-Term Memory(长期角色记忆模块)
长期角色记忆存储来自用户和聊天机器人的历史人物信息,关键是基于上下文角色匹配(CPM)模型的存储与检索操作。使用上下文编码器Ec(·)对当前上下文c进行编码,使用角色编码器Eρ(·)对角色ρi进行编码。E(·)是编码器在第一个输入令牌([CLS])上的输出,对应于输入的池表示。编码器Ec和Eρ用ERNIE模型初始化,然后在我们的DuLeMon语料库上进行训练。对于每个训练样本,我们将积极角色定义为当前用户话语和机器人响应中使用的角色(包括机器人角色和机器人看到的用户角色),而消极角色定义为当前会话的剩余角色。给定上下文c,一个积极的人格ρ+,和一个消极的人格ρ−,我们使用三重损失来调整网络
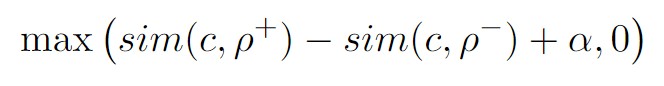
Ec和Eρ这两个编码器都是使用预训练语言模型ERNIE初始化的,目的是将原始的文本序列(上下文c或人物描述ρ)映射为一个固定长度的句子向量嵌入,方便后面进行相似度检索
角色信息记忆的存储:在Persona Memory中已经存在user persona,PE模块从对话中识别到句子包含的角色信息后,需要计算当前角色信息ρ_i与记忆中角色信息的余弦相似度,得到最接近的角色信息ρ_j,若ρ_i与ρ_j的相似度超过给定的重复阈值s_dup时,将记忆中的ρ_i替换为ρ_j;否则,直接将ρ_i写入Persona Memory。写入时,保存{ρ_i, E_ρ(ρ_i)}对以备后续读取。
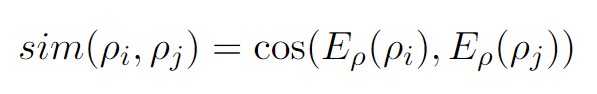
角色信息记忆的检索:读取角色是从记忆中检索的过程。首先,使用密集向量的高效相似度搜索来选择候选向量。然后利用匹配模型对候选词与当前上下文的相关性进行评分。上下文和角色之间的相似度使用余弦相似度,获取最相关的k个用户角色信息
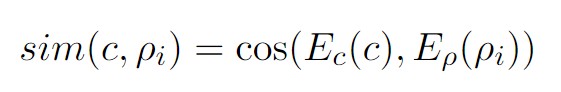
Generation Module(响应生成模块)
与一般的Seq-to-Seq的encoder-decoder结构不同,PLATO-2是统一建模双向的上下文编码和单向的回复生成,在编码阶段,利用双向的self-attention编码上下文,这样可以最大程度地捕获上下文中utterance之间的关联关系。而在解码阶段,只使用单向的masked self-attention对已生成的部分序列进行编码,确保每个生成的词只关注它前面已生成的词,这是因为在生成时,下一个词是在之前生成的基础上予以扩展,不能参考当前位置之后的信息(防止出现逻辑矛盾)。论文在PLATO-2架构上训练模型,给定上下文C、相关联用户角色信息ρ^u、聊天机器人角色信息ρ^s,任务如下:
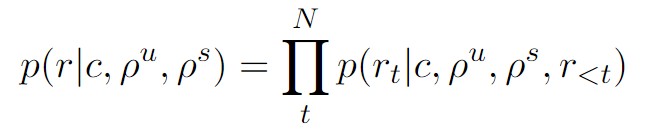
该公式表示了生成目标回复 r 的条件概率分布。根据链式法则,目标回复 r 生成的概率可以分解为生成每个词 rt 的条件概率的连乘积。因此公式右边表示以 c, ρu, ρs 和已生成的词 r<t 为条件,生成下一个词 rt 的概率的连乘积
PLATO-2通用回复生成的损失函数可表示为以下形式
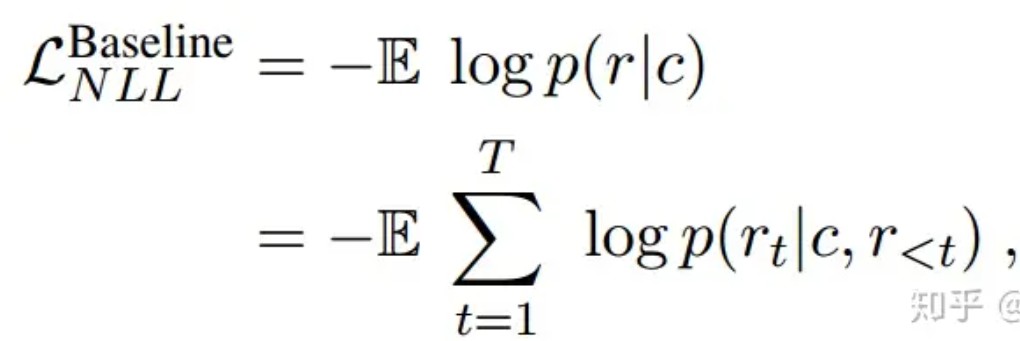
在当前任务下,损失函数中的上下文c扩展为上下文c,用户角色信息和聊天机器人角色信息,因此,我们需要最小化以下负对数似然 (NLL) 损失,得到一个能够结合角色信息回复的对话模型
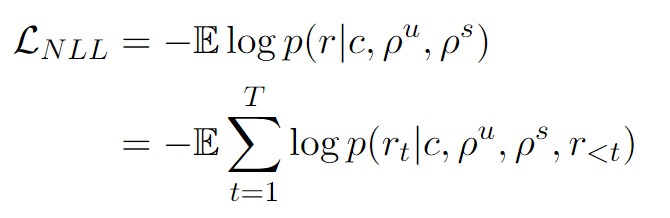
Experiments
论文方法与以下几个baselines进行对比:
- PLATO-2:基础的PLATO-2模型生成回复
- PLATO-FT:在DuLeMon数据集上微调后的PLATO-2PLATO-LTM:具有长期角色记忆的PLATO-FT模型(论文方法)
- PLATO-LTM:具有长期角色记忆的PLATO-FT模型(论文方法)
- PLATO-LTM without PE:没有角色提取器(PE)模块的PLATO-LTM,该模块将所有历史对话(用户和聊天机器人)存储到记忆模块中,而无需提取角色信息
评估指标:对于角色信息分类模型(PE),采用precision、recall、F1来评估准确性;对于长期角色记忆模块,采用AUC和recall来评估;使用PPL、BLEU、F1和DISTINCT-1/2来评估生成模型产生的响应。对于整体框架生成的最终回复采用人工评估,使用三种话语级度量,包括连贯性、一致性和参与度。三名众包工作者被要求在[0,1,2]的范围内对回应/对话质量进行评分。分数越高越好。
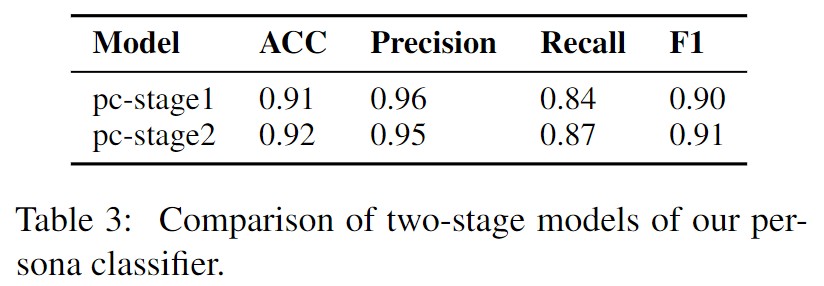
pc-stage2模型优于pc-stage1模型。表明角色提取器模型能够有效地从对话历史中识别人物信息
自动测试集上的AUC为0.76,recall为0.83,表明我们的模型可以有效地从长时记忆中检索到相关的人物角色
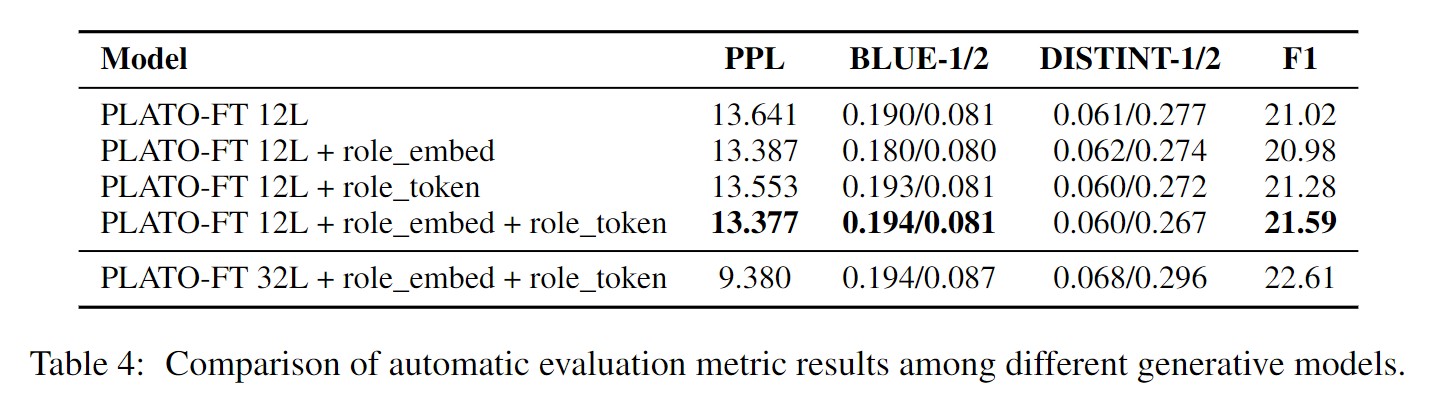
生成模型的效果反映了模型利用长时记忆内容生成反应的能力,因此选择最佳的生成模型来更好的利用检索到的角色信息来进行生成。实验结果表明,PLATO-FT + role_embed + role_token是最优算法。与PLATO-FT相比,PPL可以降低到13.377,表明两种策略都是有效的。为了进一步完善模型,我们增加了模型尺寸,用32L模型进行了进一步的训练。实验结果表明,32L模型的PPL比12L模型低4.4,F1提高2.5,可以进一步改进生成模型。因此,我们的系统采用PLATO-FT 32L + role_embed + role_token模型,其中 role_embed 、role_token这两种策略是用来区分对话中的不同角色,防止角色信息的混淆使用。
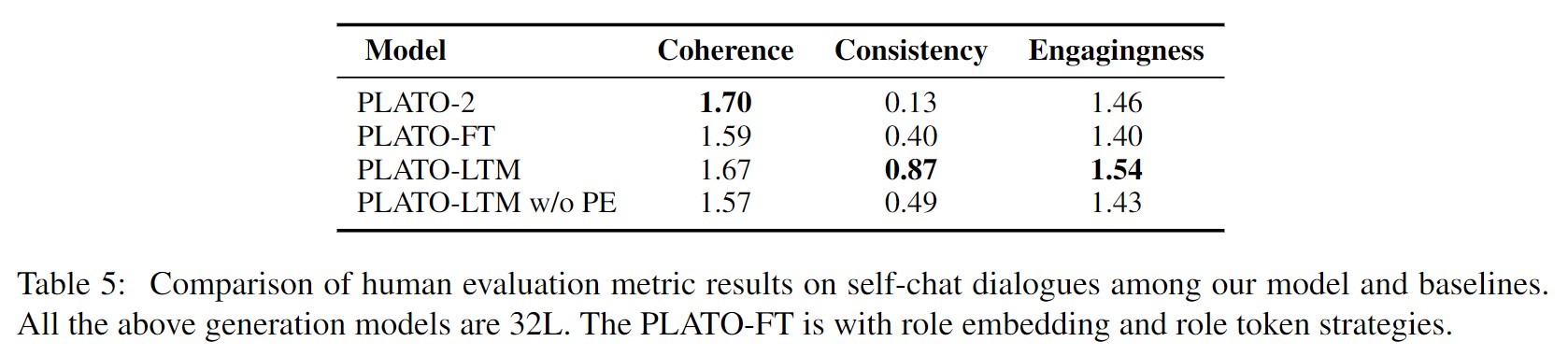
对整体模型的评估采用自聊天评估:PLATO-LTM作为用户,对比模型作为聊天机器人,每个聊天机器人与用户模拟器聊天10个episodes,每个episode包含4个长会话,每个会话包含16轮。由人工进行评估。在对话一致性方面,我们的两个模型PLATO-LTM和PLATO-FT分别可以达到0.87和0.40的分数,明显优于基线模型PLATO-2,使用长期记忆和角色提取器可以提高PLATO-FT的性能(三个方面的分数均有提高),没有角色提取器PE的PLATO-LTM模型仍然优于PLATO-FT模型。这表明没有角色提取器的长期记忆在提高角色一致性方面仍然是有效的。
Conclusion
论文提出了一个新的LeMon(长期记忆对话)任务,然后建立相应的数据集DuLeMon,将长期角色建模引入大规模生成对话模型。进一步提出了一个长期记忆(LTM)作为最先进的大规模生成对话模型的插件组件。LTM由用户记忆和聊天机器人记忆组成,其中用户记忆用于理解和记忆用户提到的角色信息,而聊天机器人记忆试图保持其角色信息随时间不断更新。实验结果表明,PLATO-LTM系统可以有效地利用对话历史中双方的角色信息,在进行长时间对话时增强对话的一致性和参与度。
- 发表于 2024-03-31 21:57
- 阅读 ( 2124 )
