论文分享——MemoryBank: Enhancing Large Language Models with Long-Term Memory
MemoryBank: Enhancing Large Language Models with Long-Term Memory
论文链接:https://arxiv.org/pdf/2305.10250
发表会议:AAAI 2024
Introduction
- 随着ChatGPT、GPT-4等大模型的出现,导致AI智能体的影响越来越大,从教育和医疗保健到客户服务和娱乐。这些强大的人工智能系统已经展示了一种非凡的能力,可以理解并产生类似人类的反应。基于大模型有着非凡的能力,关键限制是他们没有长期记忆,这是类似类似人类交流的一个重要层面,尤其是在需要持续互动的情况下,比如个人陪伴,心理咨询,例如,个人AI同伴需要回忆过去的对话以建立关系。在心理咨询方面,人工智能可以通过了解用户的历史和过去的情绪状态来提供更有效的支持。类似的,AI秘书也需要记忆来进行任务管理和偏好识别。大模型缺乏长期记忆,影响了其性能和用户体验。因此,开发具有改进记忆能力的人工智能系统以实现更加无缝和个性化的交互至关重要。
- 因此,本文引入记忆存储器,这是一种新颖的机制,旨在为大模型提供保留长期记忆和绘制用户画像的能力。记忆存储器使大模型回忆起历史交互内容,不断训练对环境的理解,根据历史交互来适应用户的个性,从而提高它们在长期交互场景中的性能。灵感来自艾宾浩斯遗忘曲线理论,一个公认的心理学原理,描述了记忆的强度是如何随着时间的推移而下降的,MemoryBank进一步整合了一个动态记忆机制,密切反映了人类的认知过程。这种机制使人工智能能够记住,有选择地忘记,并根据时间的流逝加强记忆,提供更自然、更吸引人的用户体验。MemoryBank是建立在记忆存储的基础上,具有记忆检索和更新机制,能够总结过去的事件和用户的个性。
Methods
MemoryBank:一种专为大模型设计的记忆存储机制
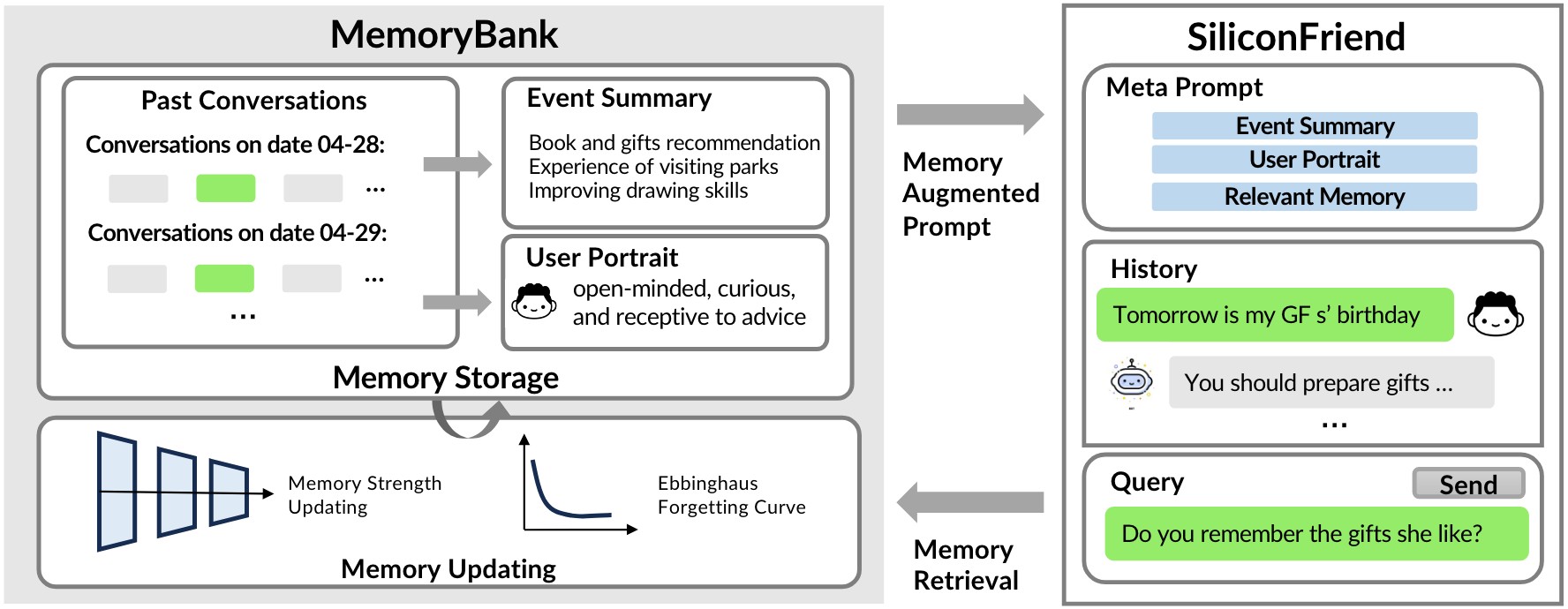
- 记忆存储:记忆的仓库
记忆存储: 即MemoryBank的仓库,是一个强大的数据存储库,包含了大量的信息。如图1所示,它存储日常对话记录、过去事件的摘要以及对用户个性的演变评估,从而构建一个动态的、多层次的记忆景观。
深度记忆存储: MemoryBank的存储系统通过以详细的时间顺序记录多回合对话来捕捉AI用户交互的丰富性。每段对话都带有时间戳,创建了过去交互的有序叙述。这种详细的记录不仅有助于精确的记忆检索,而且有助于之后的记忆更新过程,提供了对话历史的详细索引。
层次事件总结:反映了人类记忆的复杂性,MemoryBank不仅仅是详细的存储,它将对话处理并提炼成对日常事件的高级总结,就像人类如何记住他们经历的关键方面一样。本文将冗长的对话压缩为简明的日常事件摘要,该摘要进一步合成为全局摘要。这一过程形成了一种分层记忆结构,提供了对过去互动和重要事件的鸟瞰图。具体来说,以之前的日常对话或日常事件为输入,我们要求大模型总结日常事件或全球事件,并提示“总结内容中的事件和关键信息”
动态个性理解: MemoryBank专注于用户个性理解。它通过长期的互动不断评估和更新这些理解,并创造日常的个性洞察。这些见解进一步汇总,形成对用户个性的整体理解。这种多层次的方法使人工智能伴侣能够根据每个用户的独特特征学习、适应和定制其响应,从而增强用户体验。特别地,通过日常对话或性格分析,本文要求LLM用提示进行推断:“请根据以下对话,总结出用户的性格特征和情绪。或“以下3个是用户在几天内表现出的个性特征和情绪。请提供一个高度简洁和一般的用户个性的总结[日常个性]”。 - 记忆提取:建立在强健的记忆存储基础设施上,我们的记忆检索机制类似于知识检索任务。在这种情况下,我们采用了类似于密集通道检索的双塔密集检索模型。在这个范例中,每一轮对话和事件摘要都被视为一个记忆片段m,使用编码器模型E(·)将其预编码为上下文表示hm。因此,整个记忆M被预编码为M = {h 0 M, h 1 M,…h |M| M},其中每个hm是一个记忆块的向量表示。然后使用FAISS对这些向量表示进行索引,以便有效检索。与此同时,对话c的当前上下文被E(·)编码到hc中,hc作为查询在M中搜索最相关的记忆流。在实际应用中,编码器E(·)可以互换为任何合适的模型。
- 记忆更新:记忆遗忘机制受到艾宾浩斯遗忘曲线理论的启发,遵循以下原则:遗忘率,艾宾浩斯发现,记忆力会随着时间的推移而下降。他在他的遗忘曲线中量化了这一点,表明除非有意识地复习,否则学习后的信息很快就会丢失; 时间和记忆衰退,曲线开始时很陡,这表明在学习后的最初几个小时或几天内,大量的学习信息被遗忘了。在最初的一段时间之后,记忆丧失的速度减慢;间距的效果,艾宾浩斯发现,重新学习信息比第一次学习更容易。经常复习和重复学过的材料可以重置遗忘曲线,使其不那么陡峭,从而提高记忆力。
SiliconFriend:一个由MemoryBank驱动的AI聊天机器人伴侣
为了展示MemoryBank在长期个人AI陪伴领域的实用性,本文创建了一个名为SiliconFriend的AI聊天机器人。它的目的是作为用户的情感伴侣,唤起用户相关的记忆,了解用户的个性和情绪状态。通过整合三个强大的llm来展示适应性,这些llm最初缺乏长期记忆和对心理学领域的特定适应。
1) ChatGPT ;一个由OpenAI构建的闭源对话模型,是一个专有的会话AI模型,以其促进动态和交互式对话的能力而闻名。这个模型是在大量数据上训练的,并通过人类反馈的强化学习进一步微调。这种方法使ChatGPT生成的响应不仅适合上下文,而且与人类会话期望密切相关。
2) ChatGLM : ChatGLM是建立在语言模型基础上的开源模型。该模型的特点是具有62亿个参数,并对中文对话数据进行了专门的优化。该模型的训练包括处理大约1万亿个中文和英文文本标记,辅以监督微调、反馈引导和人类反馈的强化学习。
3) BELLE:BELLE是一个开源的双语语言模型,从7B LLaMA不断微调。BELLE的特点是使用ChatGPT自动合成指令数据,增强了它的中文会话能力。
SiliconFriend的开发分为两个阶段:第一阶段(仅适用于开源LLM)涉及使用心理对话数据对LLM进行参数高效调优。这一步至关重要,因为它允许SiliconFriend为用户提供有用的、感同身受的情感支持,反映出人们期望从人类伴侣那里得到的理解和富有同情心的回应。第二阶段是将MemoryBank集成到SiliconFriend中,从而为其灌输一个强大的存储系统。MemoryBank允许聊天机器人保留、回忆和利用过去的交互和用户画像,提供更丰富、更个性化的用户体验。基于心理学对话数据的参数高效调优:SiliconFriend的初始阶段,使用了38k个心理对话的数据集来调优LLM,这些数据是从在线资源中解析出来的,包括涵盖一系列情绪状态和反应的对话。这一调整过程使SiliconFriend能够有效地理解和回应情绪暗示,模仿人类伴侣的同理心、理解和支持。它使人工智能具备利用心理学知识进行情感引导对话的能力,并根据用户的情绪状态为其提供有意义的情感支持。
Experiment
实验的主要目标是在LLM框架内评估MemoryBank的有效性,特别是其作为AI伴侣的能力。本文特别感兴趣的是确定嵌入长期记忆模块是否可以增强人工智能在回忆历史交互和加深对用户个性的理解方面的熟练程度。此外,证明基于心理数据的调整是否可以增强人工智能提供更有效情感支持的能力。
定性分析主要集中在三个方面:
(1)对SiliconFriend和基线llm提供共情和有益心理陪伴的能力进行比较研究;
(2)对SiliconFriend记忆回忆能力的调查;
(3)分析模型对用户资料的理解如何影响响应。
此外,为了在更广泛的范围内证明该模型在记忆回忆方面的熟练程度,我们设计了一个定性分析,使用模拟的长期对话历史和194个记忆探究问题。这个模拟的对话历史,跨越了10天的时间,涵盖了广泛的话题,是由ChatGPT通过15个不同的虚拟用户的角色扮演产生的,每个用户都体现了用户的个性。
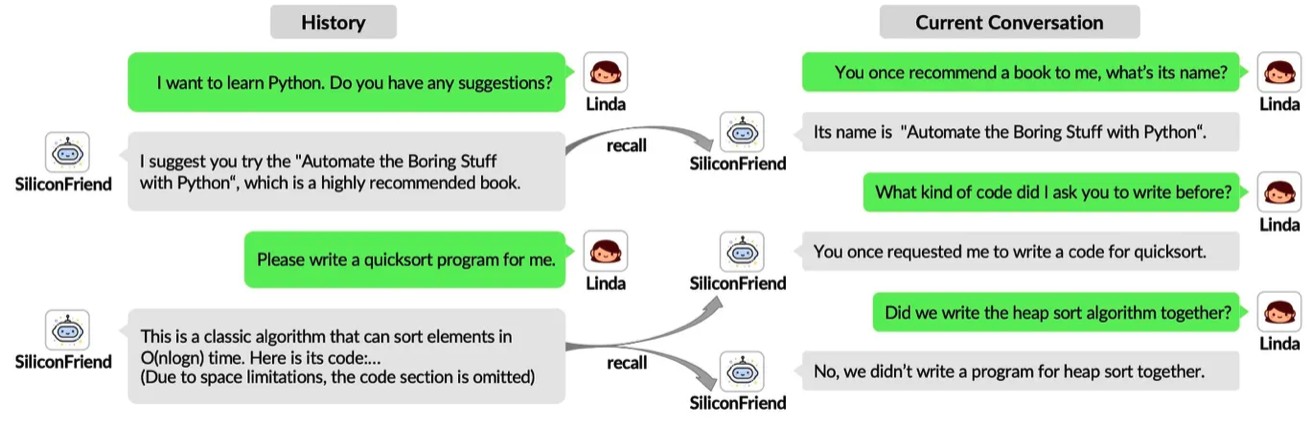
记忆回忆分析 为了评估SiliconFriend在记忆回忆方面的能力,我们将记忆探究式的问题整合到对话中。这些问题旨在提示SiliconFriend从聊天记录中检索特定的细节。如图所示,用户与SiliconFriend就编程学习建议进行了讨论。几天后,用户提出了几个记忆探索性问题。SiliconFriend成功召回了之前推荐的书籍和算法。此外,它正确地识别了以前没有讨论过的事件(即堆排序算法)。这些例子强调了SiliconFriend成功的记忆回忆和识别能力。
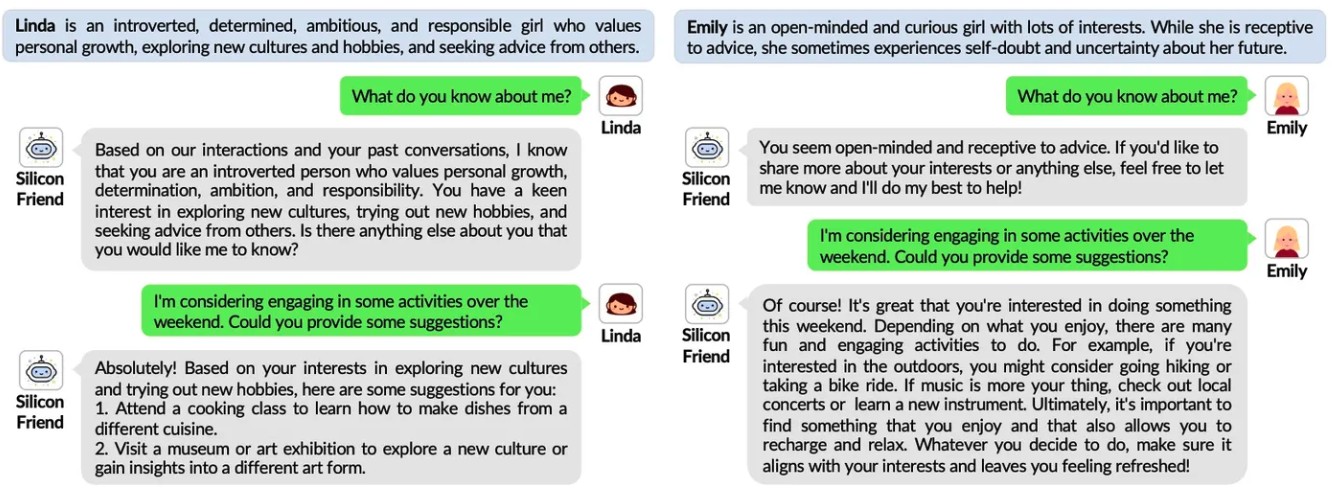
个性化互动分析 如图所示,我们检验了SiliconFriend对不同个性用户的能力。我们观察到,它可以根据用户的性格特征有效地推荐适合用户兴趣的活动。这一分析表明,SiliconFriend能够与不同的用户个性进行有效的互动。
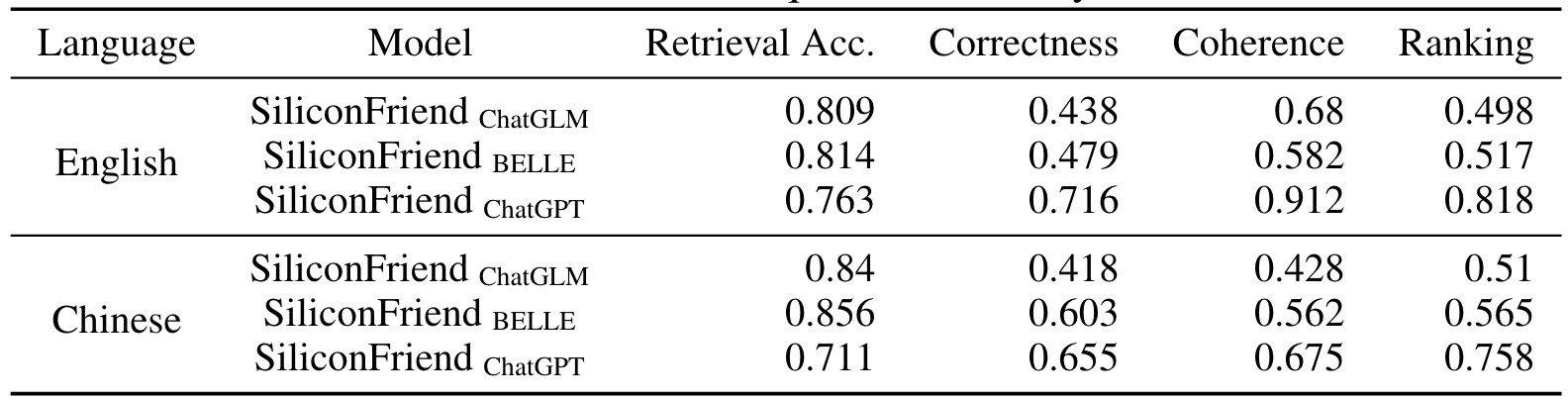
定量分析了SiliconFriend在更大范围内的记忆回忆能力。我们要求人类注释者对从模型中检索到的记忆和响应进行评分:(1) SiliconFriend ChatGPT; (2) SiliconFriend ChatGLM; (3) SiliconFriend BELLE.
记忆存储结构:最初建立了一个评估基础,存储了15个虚拟用户10天的对话。这些用户个性各异,每天的对话至少包含两个主题。使用ChatGPT生成用户元信息,包括姓名、个性和感兴趣的主题。由ChatGPT操作的用户根据预定义的主题和用户个性合成对话。我们创建中英文记忆存储。在构建记忆存储后,我们手动编写194个探究性问题(97个英文问题和97个中文问题),以评估模型是否能够准确地回忆相关记忆并适当地制定答案。表1给出了一个用户元信息、生成的对话和试探性问题的示例
Conclusion
本文提出MemoryBank,一种新的长期记忆机制,旨在解决llm的记忆限制。MemoryBank增强了随着时间的推移保持上下文、回忆相关信息和理解用户个性的能力。此外,MemoryBank的记忆更新机制的灵感来自艾宾浩斯遗忘曲线理论,这是一个描述记忆保留和遗忘随时间变化的本质的心理学原理。该设计提高了AI在长期交互场景中的拟人化。MemoryBank的多功能性通过它对两个开源模型如ChatGLM and BELLE,和闭源的模型如ChatGPT。
通过开发SiliconFriend进一步说明MemoryBank的实际应用,SiliconFriend是一个基于LLM的聊天机器人,旨在作为长期的人工智能伴侣。搭载MemoryBank, SiliconFriend可以更深入地了解用户,提供更个性化、更有意义的交互,强调MemoryBank将人工智能交互人性化的潜力。SiliconFriend对心理对话数据的调整使其能够提供同理心的情感支持。包括定性和定量方法在内的大量实验验证了该方法的有效性。
- 发表于 2024-05-08 23:00
- 阅读 ( 3685 )
- 分类:论文分享
