论文分享——Have we built machines that think like people? (Visual cognition in multimodal large language models)
Have we built machines that think like people?
(Visual cognition in multimodal large language models)
论文链接:https://arxiv.org/abs/2311.16093
发表会议:Cog-2023
Introduction
核心问题:我们是否已经制造出了能像人一样思考的机器?
拟人化进程加速:
- 早期简单的聊天机器人通过基本的模式匹配和替换方法,就能够让用户产生一种错觉,认为它具有类似人类的理解和交流能力
- 大型语言模型(LLMs)的出现:LLMs通过从庞大的数据集中学习,利用深度学习技术来生成文本,能够产生令人惊讶的、类似于人类的响应
- 强大的涌现能力:当模型扩展到更大的数据集和更复杂的架构时,会出现一些“涌现能力”,例如通过律师考试、写诗、作曲以及协助编程和数据分析任务
- 这些先进的AI系统在复杂性和能力上都远远超过了早期的聊天机器人
人机界限逐渐模糊:
- 随着LLMs能力的增强,人类与机器之间的能力界限变得越来越模糊
- 人们开始像与人类交流一样与这些系统互动,并依赖它们进行复杂的决策制定、艺术创作和人际交往
认知科学:
- 核心:判断人工智能是否能模仿人类思维
- 评估:对人类来说容易但对AI模型来说困难的领域
直觉物理学:人类拥有天生的能力来预测和理解物体的物理属性及其相互作用,这种理解包括重力、惯性和动量等概念
因果推理:人类具有直观的能力来推断、理解和预测环境中的因果关系
直觉心理学:人类具有推断和理解他人心理状态、意图和情感的固有能力
本文研究动机: 鉴于LLMs在模仿人类认知能力方面的潜力,本文的动机是评估当前视觉基础的大型语言模型在直观物理学、因果推理和直观心理学这些核心领域的表现。从三个领域中分别选取了典型任务,通过提供图像和基于语言的问题进行研究
本文创新:
- 大多数先前研究未涉及多模态LLMs,而是局限于纯文本处理
- 本研究首次探究多模态LLMs的核心认知组成部分
- 在认知科学的理论支撑下,探索了(拟人)多模态LLMs的认知能力
Methods
框架概览:
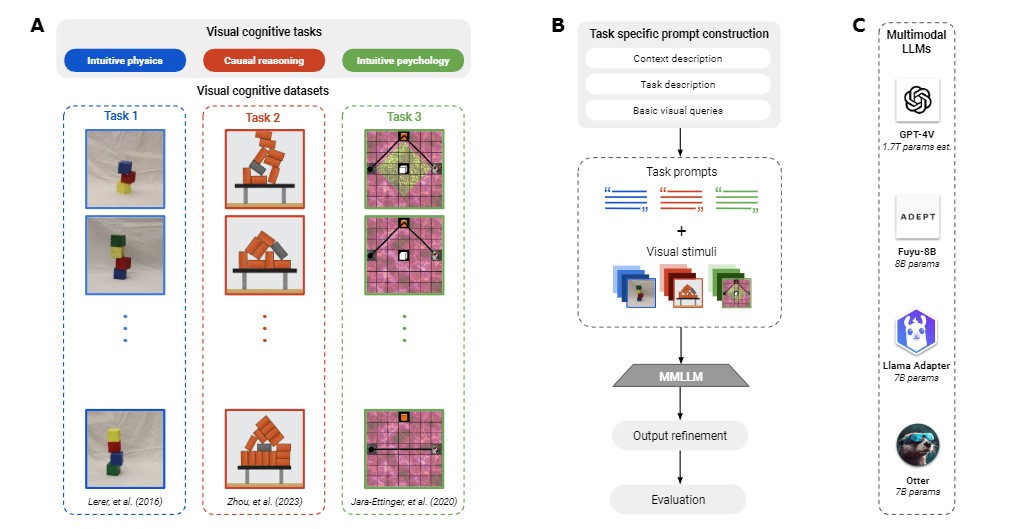
A:不同实验的图像示例。每个实验都取自三个认知领域之一:直觉物理学、因果推理和直觉心理学。
B:一般方法。每次查询时,我们都会向模型提交一张图片,并就图片提出不同的问题,即我们进行的是视觉问题解答。
C:使用多模态大型语言模型及其规模。
对于每项任务,我们都用复杂程度不断增加的任务来测试 LLMs 的视觉推理能力(见图 1C)。首先,我们询问所显示图像的简单特征,如背景颜色或所显示物体的数量。之后,我们提交了认知科学实验中的问题。我们将根据与地面实况的比较结果以及不同模型与人类数据的匹配情况进行报告
1. 直观物理学
为了测试不同 LLM 的直觉物理能力,本文使用了 Lerer 等人提出的木块塔任务。本文用这些图像在逐渐复杂的任务中测试模型,首先是确定给定图像的背景颜色,然后数出图像中彩色积木的数量,最后对所描绘的积木塔进行二元稳定性判断
2. 因果推理
在因果推理方面,依然使用积木塔任务,同样,首先要求模型数出图像中的积木,然后询问模型如果从场景中移除某个特定积木,会倒下的积木数量,最后要求模型评定某个特定积木对其他积木稳定性的责任,这项任务中的图像显示了更多的图块(从
6
到
19
不等),这使得基本的计数任务比上一节更具挑战性
3. 直觉心理学
为了测试不同 LLM 的直觉心理,本文使用了 Jara-Ettinger 等人提供的彩色背景上的宇航员合成图像数据。实验包括三个部分,其布局和组成部分略有不同。根据实验内容的不同,图像中出现了一种或两种不同的地形(以不同的背景颜色和纹理表示), 以及一种或两种不同的护理包。宇航员看到的是一条从起点通往基地的路径;宇航员可以沿途收集护理包。根据宇航员穿过的地形或他们选择是否领取的护理包,可以推断出不同地形的相关成本以及不同护理包的相关奖励。所以,我们首先让模型确定图像的背景颜色,然后让他们推断与不同地形相关的成本和与不同护理包相关的奖励
Experiment
1. 直观物理学
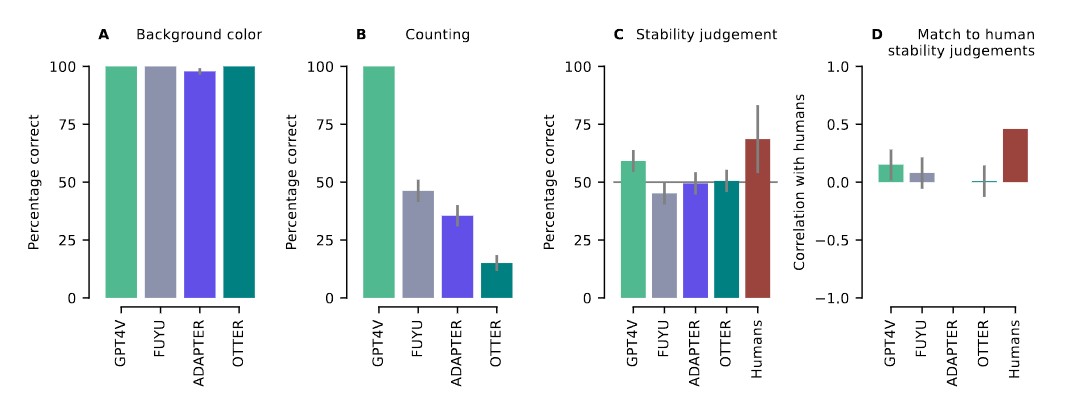
所有四个模型都能正确完成第一个也是最简单的任务:它们在确定图像背景颜色方面都达到了几乎完美的准确度。在第二项任务中,大多数模型的表现都有所下降,只有 GPT-4V 能正确判断出所有图像中的块数。第三项任务大多数模型的表现与随机结果相当,只有GPT-4V在确定积木塔的稳定性方面略高于随机结果,GPT-4V是唯一与人类判断稳定性有显著相关性的模型,但这个相关性仍低于人类之间的平均相关性。
2. 因果推理
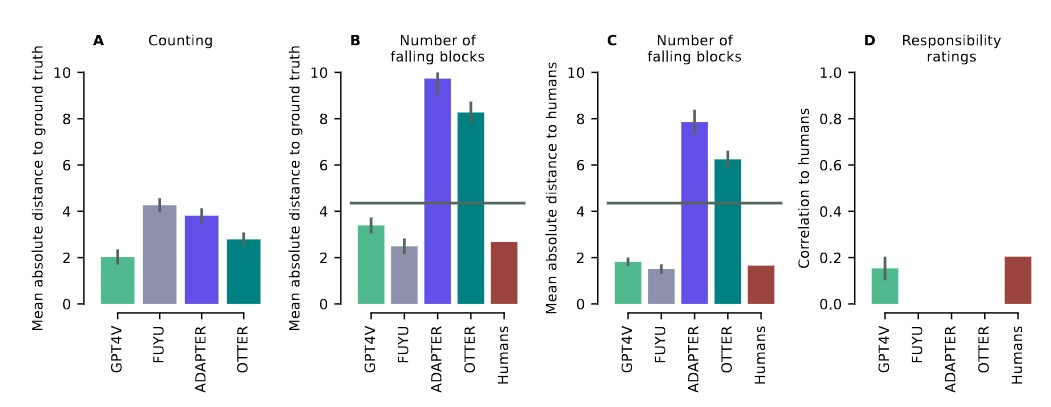
在计数任务中,依然是GPT-4结果最接近正确答案;在第二项任务中,GPT-4V 和FUYU-8B 都超过平均水平,并接近人类判断结果。在第三项任务中,除了GPT-4V,其他模型由于给出恒定评分(FUYU总是以 100 分回应,而 Otter 和 LLaMA-Adapter V2 总是以 50 分回应),所以无法定义与人类判断的相关性,GPT-4V与人类判断的相关性为0.15,尽管人类之间的平均相关性略高于GPT-4V与人类之间的相关性,但差异不显著。
3. 直觉心理学
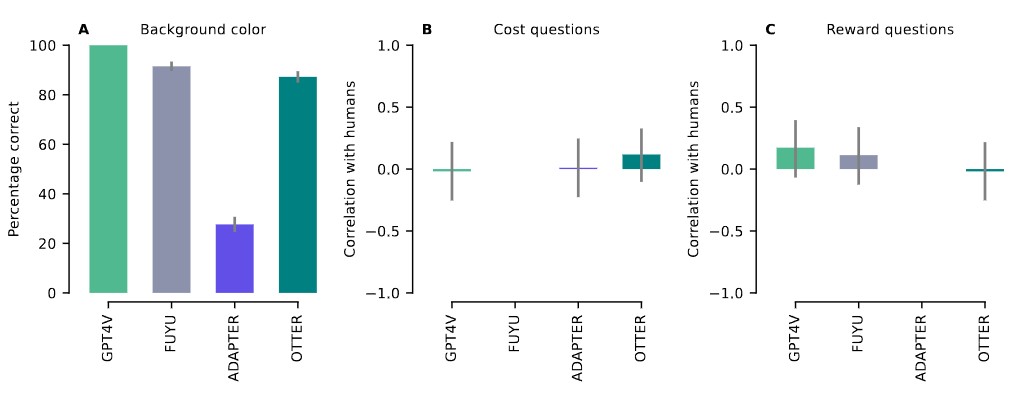
在第一个任务中,模型在确定背景颜色方面的性能比直观物理数据集差,这可能是因为这里的背景颜色不是统一的。对于任务2和3,在对环境相关成本和回报的判断上,所有模型都与人类受试者的平均值没有相关性或相关性很弱。在成本问题上,模型与人类受试者平均值的相关性从-0.02 到 0.12 不等;在奖励问题上,模型与人类受试者平均值的相关性从-0.02 到 0.17 不等(由于FUYU和 LLaMA-Adapter V2 对成本或奖励问题的评分始终不变,因此缺少相关值)
Conclusion
多模态LLMs在视觉认知能力上取得了一定进展,但在模拟人类核心认知能力方面仍有局限。 建议设计更复杂的任务,未来可以使用视频、音频等多模态数据来全面评估模型的认知能力。 考虑更多领域和不同模型,以区分LLMs模仿人类推理的能力。 思考如何在多模态模型中整合更强大的认知理解机制,提高可解释性。
- 发表于 2024-06-17 16:46
- 阅读 ( 1925 )
- 分类:论文分享
