论文分享—Overlap Communication with Dependent Computation via Decomposition in Large Deep Learning Models
论文链接:https://dl.acm.org/doi/pdf/10.1145/3567955.3567959
发表会议:ASPLOS-2023
Overlap Communication with Dependent Computation via Decomposition in Large Deep Learning Models
1.摘要
大型深度学习模型在许多任务中都显示出了巨大的具有最新成果的潜力。然而,在加速器(GPU或TPU)上运行这些大型型号是相当具有挑战性的,因为设备上的内存对于这些型号的大小来说太有限了。层内模型并行性是一种通过跨分布式加速器集群中的多个设备划分单个层或操作符来解决这些问题的方法。但是,由层内模型并行性产生的数据通信可能会占到总执行时间的很大一部分,并严重影响了计算效率。由于层内模型的并行性对于实现大型深度学习模型至关重要,本文提出了一种新的技术,通过与计算方法之间的重叠通信来有效地减少其数据通信开销。利用该技术,将一个识别出的原始通信群与依赖的计算操作一起分解为一系列细粒度的操作序列。通过创造更多重叠的机会和执行新创建的、更细粒度的通信和并行计算操作,有效地隐藏了数据传输延迟,实现了更好的系统利用率。在TPU v4荚上使用不同类型的具有100亿到1万亿参数的大型模型进行评估,提出的技术将系统吞吐量提高了1.14-1.38倍。在具有5000亿个参数的1024个TPU芯片上,实现的最高峰值故障利用率为72%。
2.动机
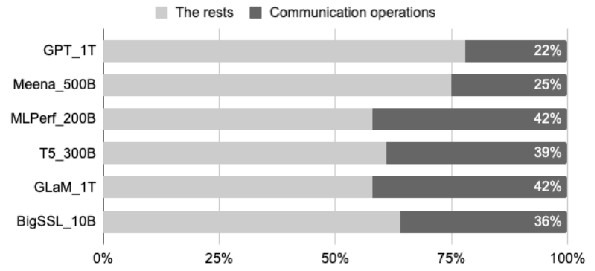
本文通过对10B到1T等不同规模大小的大模型的实验可得,由设备间的通信所产生的时延占总执行时间的22%-42%,因此对通信的优化是十分有必要的。
3.贡献
(1)本文确定了一个新的机会来重叠通信和计算通过分解而不违反数据依赖。在分布式深度学习程序中,采用层内模型并行性可以实现目标通信和计算模式。
(2)本文提出了一种通过语义等价图变换和解耦异步指令调度来最大化重叠的新方案,并且引入了一个成本模型来评估权衡,并基于净收益自动启用重叠特征。
(3)该方法已经在ML编译器XLA 中实现了这种技术,并已部署在生产中。优化在编译过程中自动执行,不需要特定的硬件,也不需要模型级别的更改。一般的思想与硬件无关,可以应用于其他编译器或ML框架。
(4)本文在2048个芯片的TPU v4上使用各种类型的大型生产深度学习模型来评估所提出的技术。评价结果显示平均加速1.2倍训练时间,降低2-3倍通信成本。系统效率显著提高,系统故障利用率高达72%。
4.方法
本文的关键思想是在每个数据碎片上分别迭代地执行部分计算、异步、非阻塞的数据通信,而不是作为一个整体来执行。为了实现这一点,一个多步骤、阻塞的通信集合需要被分解为一系列单步骤、非阻塞的通信集合。最终实现交错的通信和计算迭代。由于序列的生成方式是在同一迭代中通信和计算操作之间不存在数据依赖性的,因此每个异步、非阻塞的集合被调度与相应的分解计算并行执行。
4.1通信原语优化

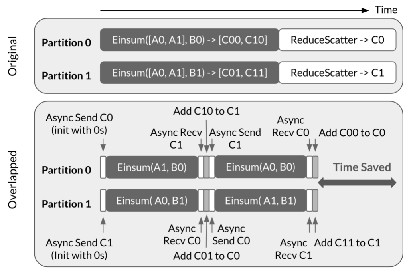 如图所示,当整个A(即[A0,A1])可用时,两个设备在AllGather之后开始执行计算。每个设备不会等待其余设备计算完成,而是异步地将最初存储在其中的数据碎片发送到另一个设备,同时使用可用的数据碎片计算部分结果。当接收到数据的后半部分时立刻开始计算,并与生成的第一部分结果合并。ReduceScatter额外需要一次计算操作,在实际训练中AllGather用于前向传播,ReduceScatter用于反向传播。
如图所示,当整个A(即[A0,A1])可用时,两个设备在AllGather之后开始执行计算。每个设备不会等待其余设备计算完成,而是异步地将最初存储在其中的数据碎片发送到另一个设备,同时使用可用的数据碎片计算部分结果。当接收到数据的后半部分时立刻开始计算,并与生成的第一部分结果合并。ReduceScatter额外需要一次计算操作,在实际训练中AllGather用于前向传播,ReduceScatter用于反向传播。
4.2循环通信
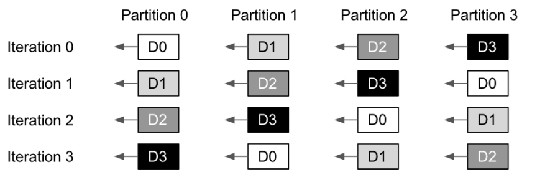
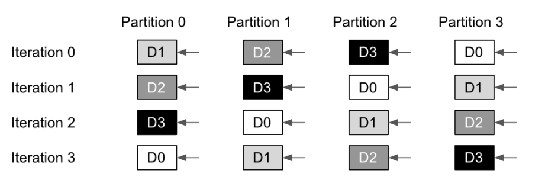
具有相应通信集合的计算被分解为一系列具有重复模式的操作,并被重构为一个循环。循环的每次迭代都对不同的数据碎片进行部分计算和相关的数据传输,并基于循环索引变量计算数据碎片ID。如图所示,一列中的Dx块(x为碎片ID)表示在每次迭代中对应的设备分区用于计算的数据碎片。在每次循环迭代开始时,AllGather中数据碎片id与循环开始时的设备分区id对齐,在ReduceScatter中则发生在结尾。纵向对比各个操作本身,数据流动与计算操作保持一致,而横向对比AllGather和ReduceScatter,AllGather在迭代1时刻与ReduceScatter在迭代0时刻相对应,这使得模型在前向传播与反向传播的过程中也可以流水线形式的并行。
4.3双向数据传输
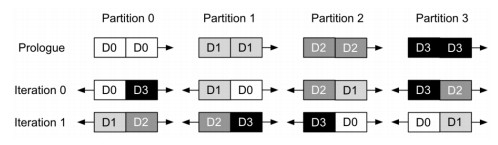
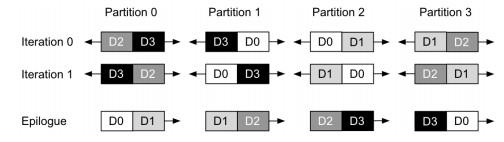
随着分区数量的增加,每个分区的计算量可能不会大到足以与相应的数据通信重叠。在这种情况下,本文采用双向数据传输来解决该问题。通过连接两个部分操作数并将它们作为单个操作执行,它有效地使每次迭代的计算量加倍。此外,双向数据传输可以充分利用TPU上专用的专用芯片互连(ICI)链路,在传输时提供高带宽,以提高系统性能。如下图所示,分别是AllGather和ReduceScatter在双向数据传输时的流程图。对于AllGather,在循环之前添加了一个初始进程。它仅将每个本地数据碎片顺时针移动1,以初始化每个设备分区上正确的数据碎片;对于ReduceScatter,需要一个结束进程来对齐结果碎片并执行操作。随着顺时针累积的部分结果碎片进一步顺时针偏移1,每个设备分区上的两个部分结果碎片具有与设备分区ID相同的数据碎片ID。
4.4融合优化
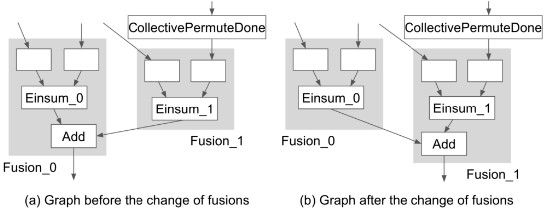
算子融合是减少缓慢的主存访问和内核启动开销的有效方法。为了在操作集合中增加更多的重叠可能,将对计算图重写。如图所示,在不进行任何优化时,数据碎片先在0设备完成计算会传输给后完成的1设备,而后需要将数据重新传回0设备完成后续计算。通过简单改变计算图中操作执行的设备,即可减少数据传输的次数,大大提升了计算性能。
5.实验
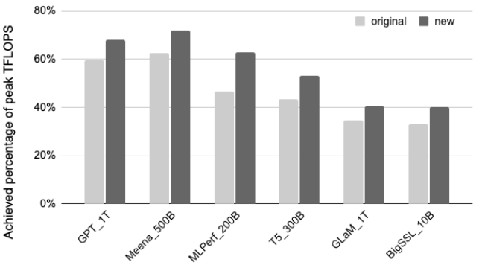
本文首先对比了不同大模型的峰值吞吐量,由实验结果可知,该方法在不同大模型下实现了平均1.2倍的性能提升。本文设计了对比实验,对比了同一种模型在不同规模下的时延。
6.结论
本文提出了一种新颖的重叠通信的并行技术,通过将计算与通信同步并行的执行来有效地减少计算中的通信开销,提高了系统的资源利用率。该方法在算法层面上的思维视角更加高层,从整个系统的运行流程考虑并行;而在具体的方法实现上更加底层,需要对通信原语和调用计算库做出修改。
- 发表于 2024-06-17 16:52
- 阅读 ( 3472 )
- 分类:论文分享
