论文分享——Space-Efficient TREC for Enabling Deep Learning on Microcontrollers
在资源有限的环境中部署深度神经网络(DNN)并获得令人满意的性能是一项挑战。尤其是在微控制器上,因为其空间和计算能力非常有限。TREC 是最近为在 DNN 中实现计算重用而提出的一种优化方法,本文的重点是如何在微控制器上实现空间和时间的节约。该解决方案在保持 DNN 精度稳定的同时,最大限度地提高了性能。实验表明,该解决方案消除了 DNN 中 96% 以上的计算,使其能够很好地融入微控制器,在仅有微小精度损失的情况下提高了 3.4-5x速度。
1 研究背景
微控制器的应用范围非常广泛,从家里的智能家居到智能穿戴设备,再到汽车等各个领域。尽管它们的计算能力有限,但通过在这些设备上本地运行DNN,可以拓展AI应用场景,减少功耗,同时在数据隐私保护方面也能得到显著提升。TREC的核心思想是,通过动态识别卷积层中输入数据的相似性,减少重复计算。由于输入数据在推理过程中经常变化,TREC可以在每次推理时适应这些变化并优化计算。这种方法不仅提高了计算效率,还能显著节省微控制器的内存资源。TREC通过减少卷积层的计算量提高推理效率,但它对微控制器的内存提出了挑战。添加TREC算子会增加额外的内存开销,主要用于哈希矩阵和簇的存储。由于微控制器的SRAM空间有限,TREC在微控制器上运行时会造成很大的存储压力,特别是在需要大量哈希表和簇信息的情况下。
2 相关工作
首先,许多研究已经通过输入复用提高DNN的计算效率,Deep reuse通过聚类相似神经元向量避免了重复计算,但带来了空间开销问题。其次,模型压缩技术通过减少模型参数有效降低了存储需求,但与输入复用技术是互补的,特别是在资源受限的微控制器上,两者需结合使用。最后,LSH通过将相似的输入向量映射到相同的哈希值,实现在线聚类,有效地减少计算量,TREC正是利用了这一技术来提高计算效率。
3 研究内容
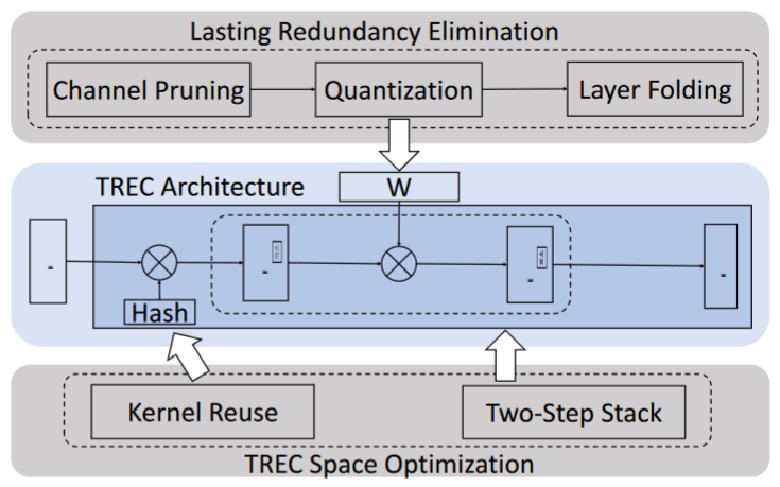
TREC架构有三个优点:
第一,通过消除瞬时冗余,TREC最大限度地减少了计算量,提升了整个网络的性能
第二,TREC兼容训练和推理任务,可以轻松替换标准神经网络中的层,保持模型的高精度
第三,TREC与去除持久冗余的方法(量化、剪枝等)能够耦合使用
然而TREC会带来额外的内存开销。为实现空间效率,本文:
- 设计了一种内核重用技术来减少TREC存储参数的空间,消除额外的空间开销
- 引入了两步堆栈替换方法和反向索引存储聚类 ID ,最小化存储簇信息的空间占用
- 此外,通过将方法集成到反向传播中,与原始 TREC技术 相比保持了推理精度
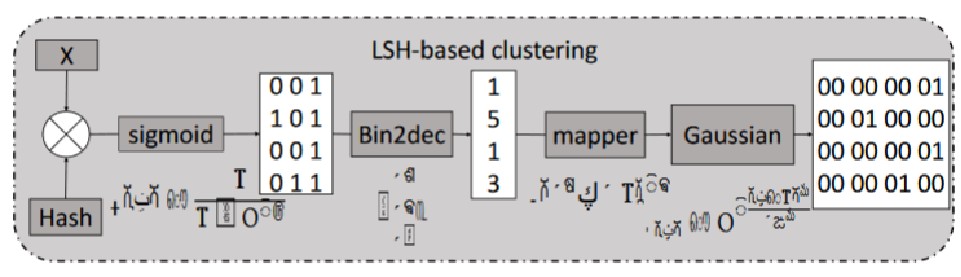
深入分析现有TREC的计算过程:
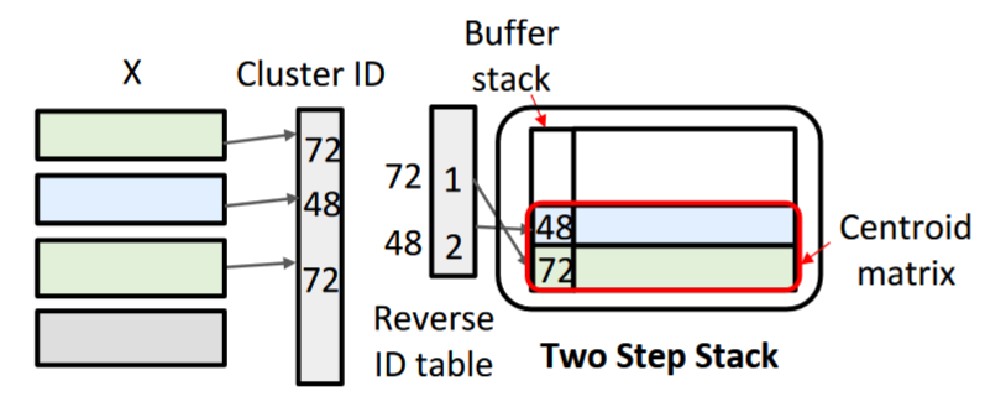
- 数据哈希映射:使用哈希矩阵将输入数据映射为二进制向量,每个向量生成一个聚类标识符(ID),相似的向量被分配相同的 ID
- 相似向量聚类:根据相同的 ID 将相似的神经元向量聚集成簇
- 簇中心计算:计算每个簇的中心向量,作为簇内所有向量的代表,避免重复计算
可以发现,TREC的额外空间占用主要来自于:哈希矩阵和向量聚类
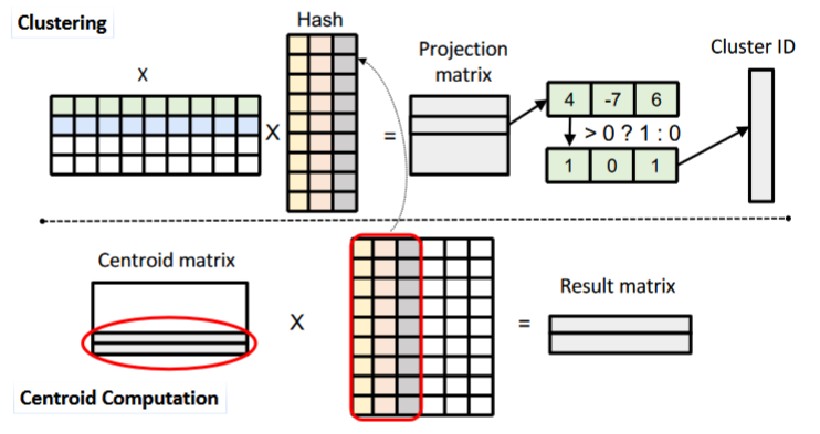
模块一:卷积核重用技术-减少哈希矩阵开销
传统TREC方法为哈希矩阵单独分配内存,导致了不必要的空间开销。如何在不牺牲存储空间的情况下保证哈希运算的高效性成为一个核心问题。
本文提出:
复用卷积层卷积核矩阵的前几列作为哈希矩阵,进行输入数据的在线哈希聚类,减少了哈希矩阵所需的额外内存消耗。
在训练过程中,哈希矩阵的梯度直接从对应的权重矩阵中提取,避免了独立更新哈希矩阵和权重矩阵时产生的误差问题。
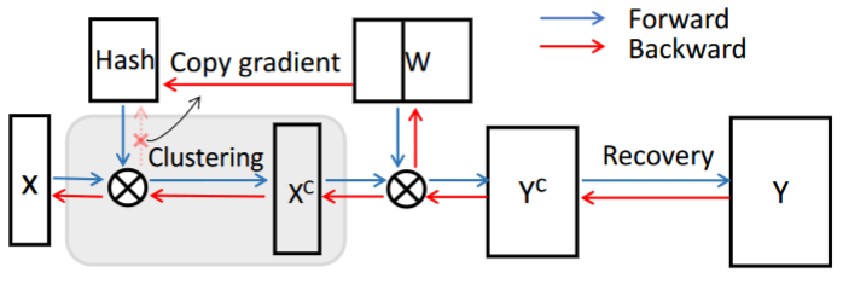
由于卷积核独立训练,因此卷积核的列是相互独立的。这保证了哈希运算结果彼此独立。
模块二:两步堆栈替换方法-减少向量聚类开销
传统TREC通过预先分配固定大小的数组存储聚类的神经元向量,导致空间浪费。此外,为每个聚类单独存储完整向量和索引表占用大量内存,难以适应微控制器的空间限制。本文采用反向ID表(Reversed ID Table)存储每个聚类的代表性向量的指针,避免为每个聚类分配完整的存储空间。还通过使用堆栈来存储每个聚类的代表性向量,确保在任意时刻仅存储聚类的中心向量,减少空间开销。
4 实验验证
实验设置:
- 硬件:STM32F469I(324KB SRAM, 2048KB Flash)STM32F746ZG(320KB SRAM, 1024KB Flash)
- 数据集:CIFAR-10
- 模型:CifarNet, ZfNet, SqueezeNet
- DNN训练配置:20核 Intel Core i7-12700K,128GB RAM,NVIDIA GeForce RTX A6000,48GB显存
- 训练框架:PyTorch 1.10.1
TREC通过利用权重矩阵的部分内容作为哈希矩阵,减少了对外部字典的多次内存访问。这降低了内存带宽的需求,从而减少了内存访问的瓶颈。TREC优化了矩阵乘法操作,特别是在采用SIMD指令时,通过减少数据转置和提高计算效率,从而加速了推理过程。
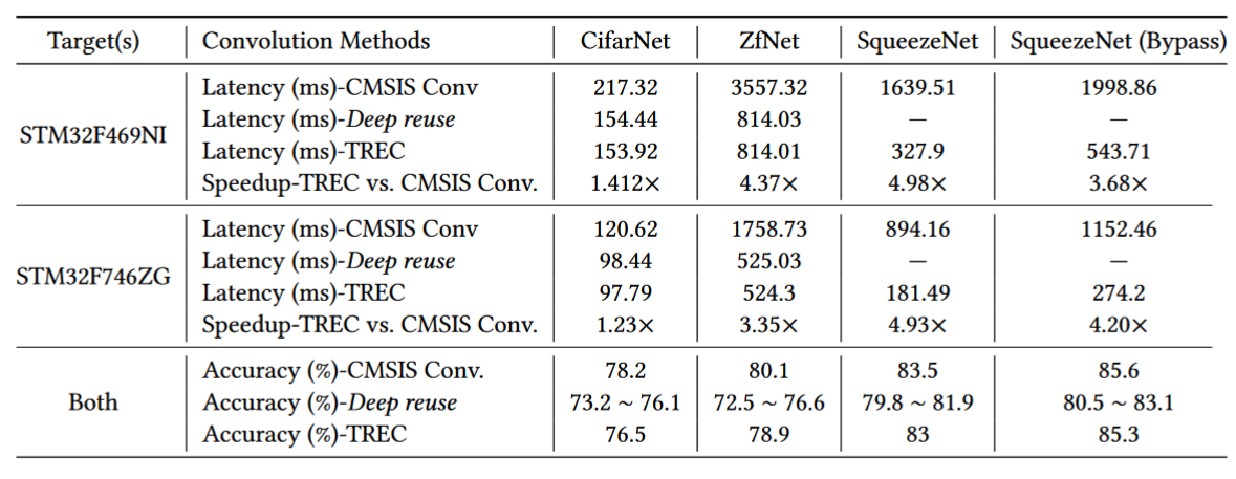 通过优化TREC空间占用,降低了TREC对外存的访问次数,大幅提升了推理速度(1.23x~4.98x)
通过优化TREC空间占用,降低了TREC对外存的访问次数,大幅提升了推理速度(1.23x~4.98x)
对于卷积层而言,TREC能够去除特征图约96.22%的瞬时冗余,从而实现平均4.28倍,最高18.66倍的速度提升。TREC在计算密集型层中效果十分显著,例如SqueezeNet扩展层。
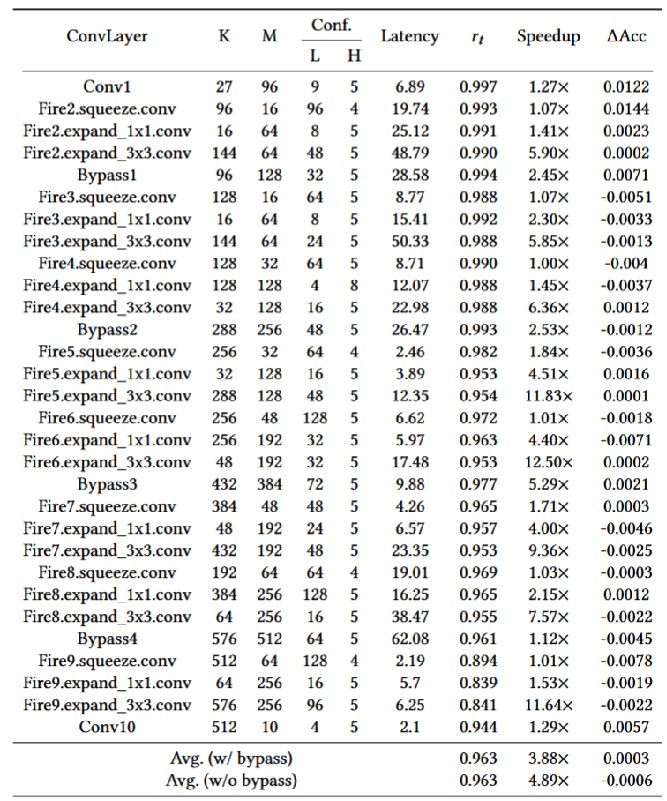 TREC在卷积层中实现了显著的速度提升,在最小化准确性损失的同时实现了高效计算
TREC在卷积层中实现了显著的速度提升,在最小化准确性损失的同时实现了高效计算
内核重用对精度稳定性影响较小,随着内核重用的层数 (G) 增加,精度会缓慢下降,但在G < 16时仍能保持在84%以上。
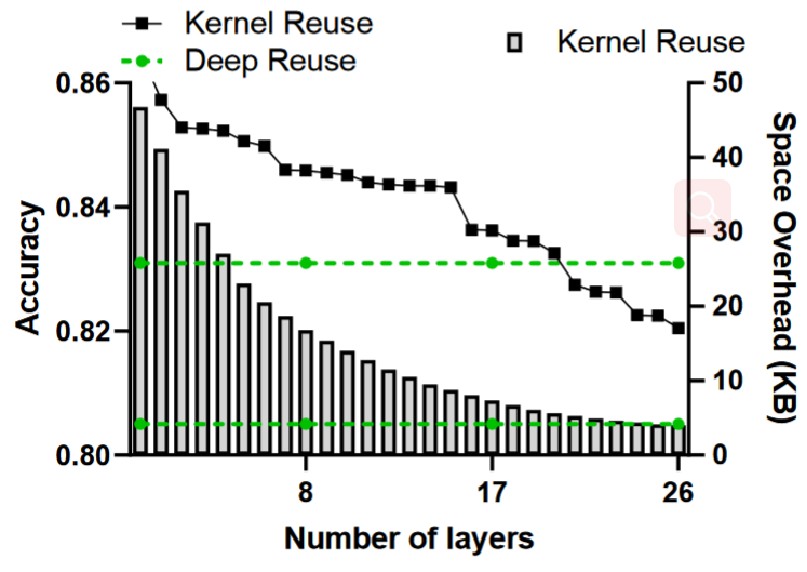 将内核重用应用于少量层可以显著减少空间开销,同时几乎不降低精度
将内核重用应用于少量层可以显著减少空间开销,同时几乎不降低精度
5 总结与思考
总结:
本文通过引入空间高效的 TREC 来在微控制器上高效执行深度神经网络,使微控制器的资源利用能力达到最佳。在评估中,所提出的方法通过降低TREC的内存占用和对外存的访问次数,实现了 3.5x-5x 的加速而几乎没有精度损失。
思考:
- 尽管内核重用已经在空间与精度之间取得了一定的平衡,但随着内核重用层数的增加,精度下降较为明显。未来可以探索更先进的内核重用算法或自适应机制,减少精度损失。
- 该研究目前评估了CifarNet、ZfNet和SqueezeNet等微控制器友好型网络,未来可以研究如何将TREC扩展到更复杂和深层的模型上,比如ResNet、Transformer等,进一步验证其适用性。
- 发表于 2024-09-18 20:45
- 阅读 ( 1866 )
- 分类:论文分享
