四足机器人&&强化学习(二)
本体感知+视觉输入
ETH 2022 -- Learning robust perceptive locomotion for quadrupedal robots in the wild
这篇工作和ETH2020的主要区别在于使用了感知信息 (视觉、雷达)使四足能够获得更加完备的信息。
Attention-based Recurrent Encoder
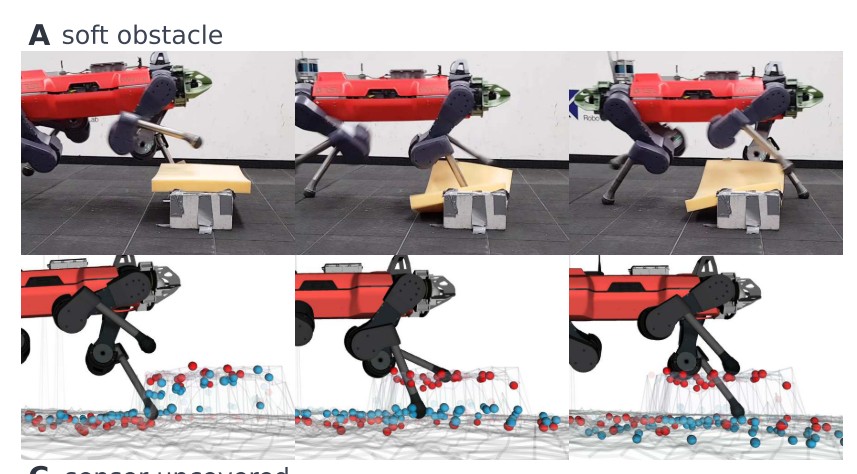
提出了一个基于attention机制的 belief state encoder,可以融合感知信息和本体信息,同时可以对未来进行一定的推断。例如,智能体在通过下图的软体材质时,belief 编码器会记录这一信息,并在后面时间步的推断中修改对地形信息的估计。
Privileged Learning
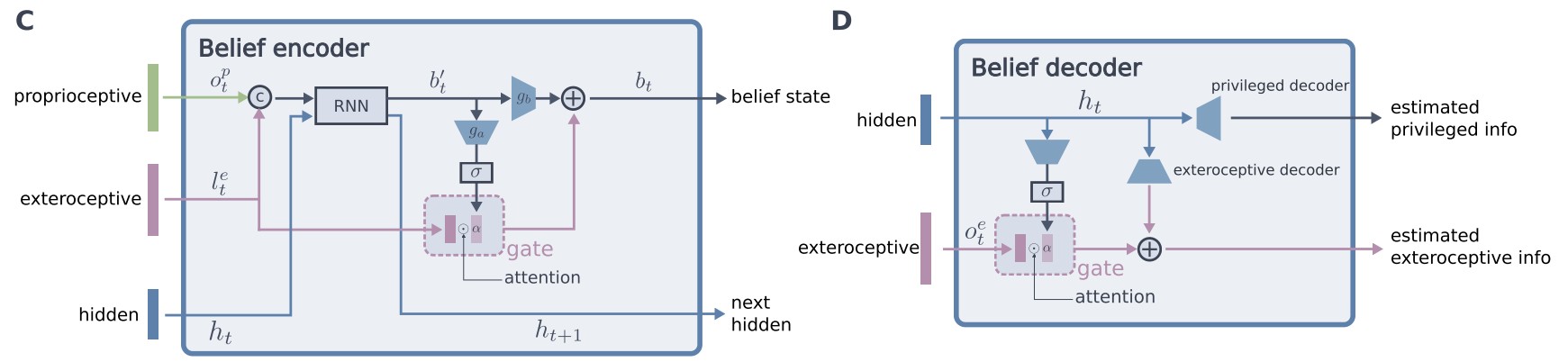
在学习上仍然沿用了ETH2020的做法,首先在仿真环境中利用完备的感知信息和本体信息,基于强化学习算法训练一个 teacher 策略。随后 student 使用 belief state encoder 作为状态信息的编码使用 teacher 策略产生的动作作为监督信息,通过策略蒸馏得到 student 策略。belief state 的优势是能够通过历史信息推断智能体所看不到的部分信息,从而解决部分可观测的问题。在实际训练中,本文方法也使用了其他的技巧,例如 curriculum Learning, randomization 等。下图显示了belief encoder 的具体结构,encoder-decoder 的结构在策略蒸馏损失的基础上,额外的给出了reconstruction 的损失,可以用于加速学习 belief state。
CMU 2021 -- Coupling Vision and Proprioception for Navigation of Legged Robots
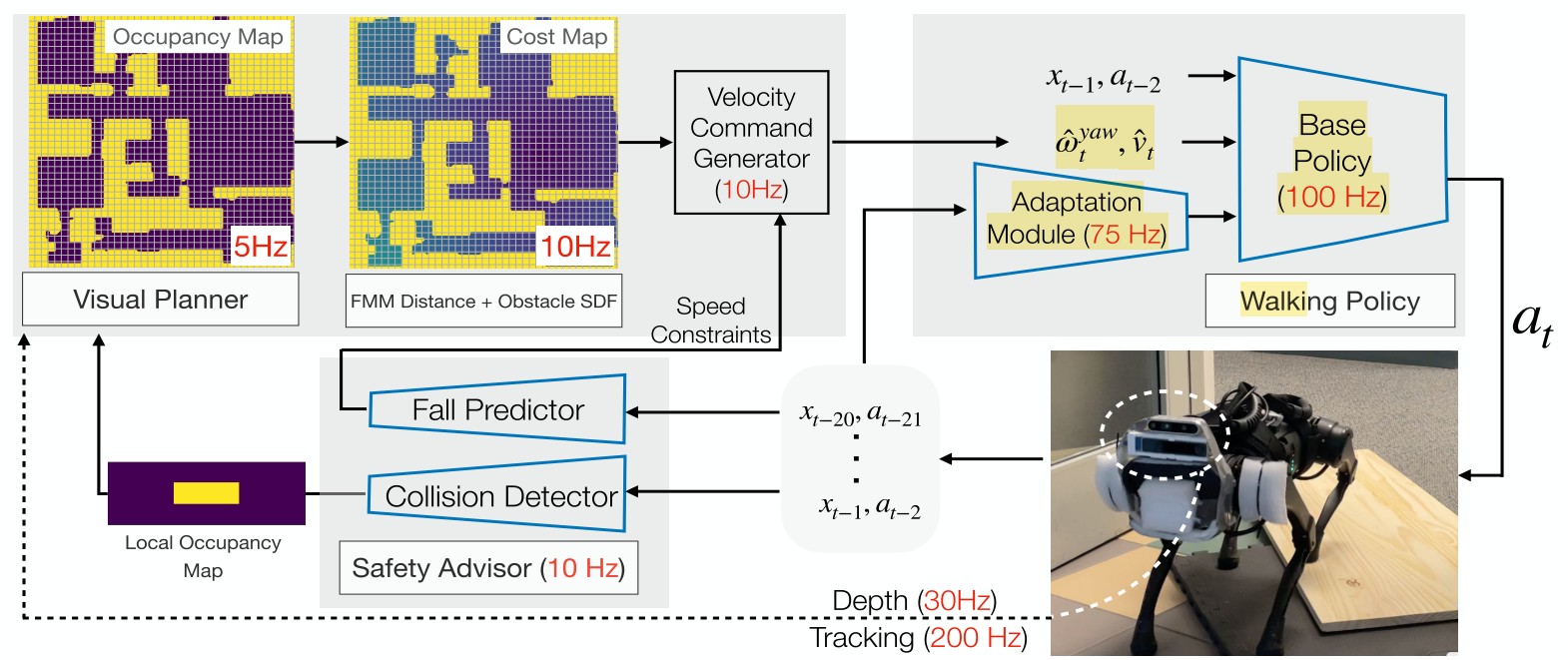
本文结合视觉模型,提出了一个较为复杂的机器人导航和行走相结合的结构,包含三个部分:Planner, Safety advisor, Walking policy。在执行实际的 Goal-conditional 任务中,由这三个方面进行协调来获得好的策略。
Walking Policy 是最基础的模块,利用四足机器人的本体信息,在 simulation 中使用 RL 算法训练得到一个行走策略。在实际的 apply 中,由于四足获得的信息和仿真器中获得的完备信息不同,需要训练一个监督学习的模型,使用四足实际的状态序列和动作序列来预测 true extrinsicsvector,从而使实际运动中的信息和仿真器信息相互匹配。
Safety advisor 包括两个部分,第一部分是一个 Collision Detector,使用监督学习的方法进行训练,在仿真器中通过机器人的本体信息来预测发生碰撞的概率。如果预测到大概率会发生碰撞,会修改 planner 中产是的 cost map 来使 planner 规划一条绕过当前障碍物的路径。第二部分是 Fal Predictor,输出的也是一个概率值,表示智能体是否会有倾倒的可能,在仿真器中使用监督学习的方法进行训练。在实际使用中,如果输出的倾倒概率较高,则会降低 command 中的期望速度:反之则会提升期望速度。通过改变期望的速度来使智能体避免倾倒。
Visual Planner 是一个基于视觉的模块,包含几个部分:
1. Mapping Module: 根据 onboard camera 生成一个俯视的 2D occupancy map。在四足行走过程中,使用深度相机获得点云数据只,并转换为世界坐标系,从而对四足所在位置进行估计,将估计投影成一个2D平面图。
2. Cost map 生成: 使用 Fast marching method (FMM) 来计算当前位置到目标位置的集合距离;通过FMM来计算当前位置到最近的障碍物的距离。Cost计算需要同时考虑goal和障碍物: 当前位置距离Goal的位置越近,cost 越高;如果当前位置距离障碍物的距离越近,则cost越低。
在生成 cost map 之后,基于 cost map 可以计算最优的 command,其中包括四足的前进方向和角度,command 跟随 cost map 的 negative gradient 方向来进行训练,目标是选择使 costmap 最小的命令。
UC San Diego 2022 -- Learning Vision-Guided Quadrupedal Locomotion End-to-End with Cross-Modal Transformers
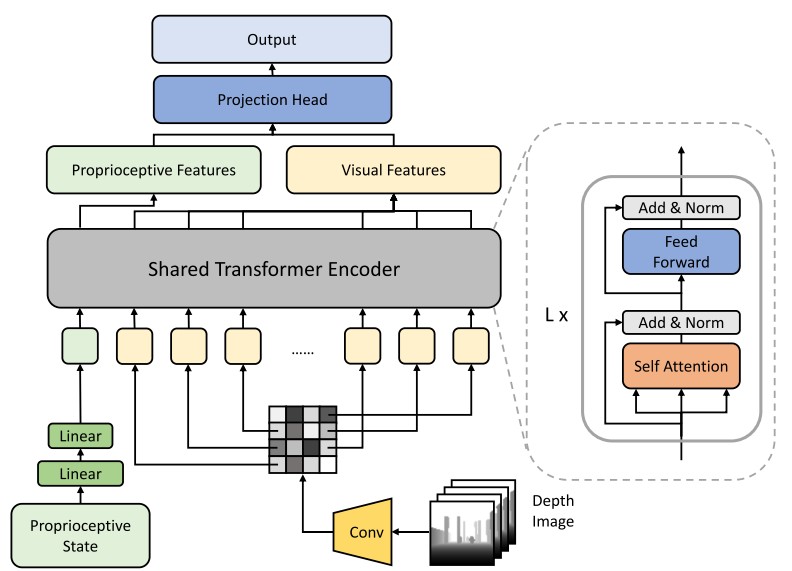
本文的 motivation 是之前多数的四足机器人工作仅依靠机器人本体状态 (proprioceptivestate,包括 pose, imu,joint rotations) 等,而忽略了周围环境的信息,导致机器人在跨越障碍物中缺乏了许多环境信息。本文使用Transformer 网络来结合机器人的本体状态和视觉信息 (深度相机),从而在进行决策中能够同时考虑本体状态和环境信息。模型结构如下图所示。具体的Proprioceptive input 是一个 93d 的向量,视觉信息的输入是一个深度图 (64*64) 。本体状态和视觉信息分别用不同的编码器进行编码,随后使用 transformer 结构进行跨模态的 attention 操作,最后使用 projection head 将跨模态的信息进行融合。
整个模型使用PPO算法进行训练,上述的网络结构中,本体信息的编码器和视觉编码器在值函数网络和策略网络之间进行公用,随后值函数网络和策略网络分别输出值函数估计和动作。结果表明本文提出的模型相对于 state-only 和 depth-only,或者简单的 state-depth concat 的方法都有较为明显的性能提升。
- 发表于 2023-02-06 18:09
- 阅读 ( 2883 )
- 分类:群智协作增强机理
