论文分享--The Shapley
摘要
本文提出了在多智能体强化学习(MA)中通过奖励对其他智能体的行为产生因果影响的智能体实现协调和沟通的统一机制。因果影响的评估使用反事实推理。在每个时间步骤中,一个智能体模拟它可能采取的替代动作,并计算它们对其他智能体行为的影响。导致其他行动者行为发生更大变化的行为被认为是有影响力的,并会得到奖励。本文如何证明,这等价于对具有高交互信息的行为者进行奖励。实证结果表明,在具有挑战性的社会困境环境(SSD)中,这种影响导致协调和沟通的增强,显著增加了深度强化学习智能体的学习曲线,并导致更有意义的学习通信协议。通过使用深度神经网络使各智能体学习其他智能体的模型,可以以分散的方式计算所有智能体的影响力奖励。相比之下,MA环境中紧急沟通的关键先前工作无法以分散的方式学习不同的政策,不得不求助于集中培训。因此,这一影响为这一领域的研究提供了新的机会。
自己总结
对奖励函数进行改进,在原有环境奖励的基础上增设了影响力(因果影响反事实推理)奖励,使得智能体在每次选择动作时会选取导致其他行动者行为发生更大变化的行为,影响力奖励增设导致协调和沟通的增强,显著增加了深度强化学习智能体的学习曲线,并导致更有意义的学习通信协议,并且影响力奖励是以分散的方式进行计算,摆脱了紧急沟通之前的集中式限制。
引语
强化学习的内在动机
1.是指允许个体在不同的任务和环境中学习有用行为的奖励功能,有时没有环境奖励,之前的内在动机研究方法通常关注好奇心或赋权。在此,本文考虑了多智能体强化学习中从其他智能体派生内在社会动机的问题。
2.之前有一些研究研究了的内在社会动机工作依赖于特定于环境的手工奖励,或允许智能体查看其他智能体获得的奖励。这样的假设使得不可能实现跨多个环境的MA智能体的独立训练。
实现MA中各智能体之间的协调仍然是一个难题
在此领域之前的工作,经常采用集中培训来确保智能体学会协调。虽然智能体之间的通信有助于协调,但训练应急通信协议仍然是一个具有挑战性的问题;最近的实证结果强调了学习有意义的应急沟通协议的难度,即使依赖集中培训
本文提出一种统一的方法通过给对其他智能体行为产生因果影响的智能体一个内在奖励来实现MA中的协调和沟通。因果影响的评估使用反事实推理;在每个时间步骤中,一个智能体模拟它可能采取的替代的、反事实的行动,并评估它们对另一个智能体行为的影响。导致其他智能体行为发生相对较大变化的行为被认为具有高度影响力并获得奖励。本文展示了这种奖励是如何与最大化行为主体之间的相互信息相关联的,并假设这种归纳偏差将驱动行为主体学习协调行为。
连续的社会困境(SSD环境)
连续社会困境(SSDs)是具有博弈论收益结构的部分可观察、空间和时间扩展的多主体博弈。个体可以通过背叛、非合作行为在短期内获得更高的回报(因此是出于贪婪的动机而背叛),但如果所有的个体都合作,每个个体的总回报会更高。因此,在这些ssd中,一组智能体获得的集体奖励可以清楚地表明智能体学习合作的程度
本文尝试了两个ssd,一个是公共物品游戏《cleanup》,另一个是公共资源池游戏《harvest》。在这两款游戏中,苹果都提供奖励,但都是有限的资源。智能体必须协调其他智能体的收获苹果行为,以实现合作。这些游戏的代码可以在开源软件中找到
正如《补充材料》图2中的谢林图所揭示的那样,所有的智能体都将从这些博弈中学习合作中受益,因为即使是被利用的智能体也会比有更多智能体叛变的情况下获得更高的奖励。然而,传统的智能体很难学会协调或合作有效地解决这些任务。因此,这些ssd代表了具有挑战性的基准任务的社会影响力奖励。影响主体不仅必须学会协调自己的行为以获得高回报,还必须学会合作。
SSD环境下的的多智能体强化学习
<S,T,A,r>,智能体在部分可观测环境下被训练最大化个人奖励
t时刻s状态a动作T状态转换r奖励奖励可能取决于其他智能体的行为。汇总成为历史轨迹
神经网络由卷积层、完全连接层、长短期记忆(LSTM)循环层和线性层组成。所有的网络都以图像作为输入和输出策略pi,和价值函数V
基本的社会影响
社会影响内在动机会因为一个行为人对另一个行为人的行为产生了因果影响而给予额外的奖励。所以智能体的奖励变为外部奖励和因果影响奖励之和。
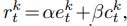
如果k智能体不采取当前动作,j智能体的行为会发生什么变化。通过多次采样平均结果,获得智能体j的最终策略
因为智能体j由于智能体k的动作,策略发生了变化,所以智能体k的动作会产生一个因果奖励
公式1中的奖励与主体行为之间的交互信息(MI)有关,训练智能体使其行动之间的MI最大化,会导致更协调的行为。
此外,随着环境中智能体数量的增加,策略梯度更新的方差也会增加。这个问题会阻碍大规模MA任务收敛到均衡。社会影响可以通过在每个智能体的行动中引入显式依赖来减少政策梯度的差异。这是因为智能体接收到的梯度的条件方差将小于或等于边缘方差
注意,本文做了两个假设:
1)本文使用集中训练直接从智能体j的策略计算teckt
2)本文假设影响是单向的:接受影响奖励训练的智能体只能是未接受影响奖励训练的影响者(影响者和被影响者的集合是不相交的,影响者的数量在[1,N−1])。
这两个假设在后面的章节中都有所放松。第8节提供了关于因果推理程序(包括因果图)的更多细节和进一步解释。
实验一:基本影响
图1显示了使用基本影响奖励对标准A3C智能体进行培训的智能体的测试结果,以及智能体不接受影响奖励的模型的一个简化版本,但是,他们能够根据其他智能体的行为来调整他们的策略(即使其他智能体不在智能体对环境的部分观察视图内)。本文将这种烧蚀模型称为可见行为基线。在这个结果图和所有其他结果图中,本文使用5个随机种子测试的最佳超参数设置来测量获得的总集体奖励。误差条显示随机种子的99.5%置信区间(CI),在200个智能体步骤的滑动窗口内计算。本文采用一种课程学习方法,逐步增加社会影响奖励在C步骤(C)中的权重∈[0.2−3.5]×108);这有时会导致在影响模型的性能改善之前出现轻微延迟。
如图1a和1b所示,引入对其他智能体行为的意识会有所帮助,但在这两个游戏中,拥有社会影响力奖励最终会导致显著更高的集体奖励。由于SSD游戏的结构,本文可以推断,获得更高集体奖励的智能体学会了更有效的合作。在收获季节MA设置,显然,影响奖励对于实现任何合理的学习都是至关重要的。

图1:实验1中获得的集体奖励总额。受影响(红色)训练的药剂明显优于基线和消融药剂。在收获中,影响力奖励对于实现任何有意义的学习都至关重要。
为了了解社会影响力如何帮助智能体实现合作行为,本文研究了高得分模型在清理和收获中产生的轨迹;分析揭示了有趣的行为。例如,在这里提供的清理视频中:https:\/\/youtu。be\/iH_V5WKQxmo一名特工(以紫色显示)接受了社会影响力奖励培训。与其他智能体不同,它们在等待苹果产卵时继续随机移动和探索,而影响者只在追逐苹果时遍历地图,然后停止。剩下的时间它会保持静止。

图2:当紫色影响者在黄色影响者的视野(黄色框)外发出苹果(绿色瓷砖)的信号时,会产生巨大影响。
图2显示了影响者和黄色影响者之间的高影响力时刻。影响者选择了一个不属于黄色智能体以自我为中心的视野的苹果。因为影响者只有在苹果可用时才会移动,这会向黄色智能体发出信号,表示苹果必须在其上方,而它看不见。这改变了黄色药剂在其计划行动p(ajt|AKt,sjt)上的分布,并允许紫色药剂获得影响力。当进水者向正在清理河流的智能体发出信号,表示静止不动不会出现苹果时,也会出现类似的情况(参见补充资料中的图14)
在这个案例研究中,影响者智能体学会了将自己的行为作为二进制代码来使用,以表示环境中是否有苹果。本文在收获时也观察到类似的效果。这种基于动作的交流可以比作冯·弗里希(vonFrisch,1969)发现的蜜蜂摇摆舞。显然,影响力回报不仅产生了合作行为,还产生了紧急沟通。
考虑影响报酬的局限性是很重要的。它是否总是会产生合作行为,可能取决于环境和任务的具体情况,以及环境和影响回报之间的权衡。虽然可以说,影响对于协调是必要的(例如,两个协调操纵一个对象的智能体在其行动之间必须具有高度的影响),但也可能以非合作的方式影响另一个智能体。这里提供的结果表明,影响力回报确实导致了合作的增加,尽管在这些环境中很难实现合作。
有影响力的沟通
鉴于以上结果,本文下一个实验是使用影响奖励来训练智能体使用显式沟通渠道。本文从研究中得到一些启示,这些研究将影响和人类学习中的交流联系起来。根据Melis&Semmann(2010)的研究,人类儿童在参与合作活动时会迅速学会利用交流来影响他人的行为。他们解释说,“这种通过交流影响伴侣的能力被解释为与他人形成共同目标的能力的证据”,并且这种能力可能是“允许人类参与广泛合作活动的能力”。

图3:通信模型有两个头部,分别学习环境策略πe和发送通信符号的策略πm。其他智能体的通信消息mt−1是LSTM的输入
因此,本文为智能体人配备了一个明确的沟通渠道,类似于Foerster等人(2016)使用的方法。在每个时间步,每个智能体k选择一个离散的通信符号mkt;对于N个智能体,这些符号被连接成一个组合消息向量mt=[m0t,m1t…mNt]。然后,在下一个时间步中,将此消息向量mt作为输入提供给每个其他智能体。请注意,之前的研究表明,自利智能体人没有学会有效地使用这种不固定、廉价的谈话沟通渠道(克劳福德和索贝尔,1982年;曹等人,2018年;弗斯特等人,2016年;拉扎里杜等人,2018年)。
为了训练智能体进行通信,本文用一个额外的A3C输出头来扩充本文的初始网络,该输出头学习通信策略πm和值函数Vm,以确定要发射哪个符号(见图3)。用于在环境中行动的正常策略和价值函数πe和Ve仅通过环境奖励e进行培训。本文使用影响奖励作为培训沟通策略πm的额外激励,因此,r=αe+βc。反事实被用于评估前一时间步对智能体的通信消息的影响程度,mkt−1,关于另一个特工的行动,ajt

重要的是,通过通信信道奖励影响不受上一节中提到的限制,即可能以非合作方式影响另一个智能体。本文看到这一点有两个原因。首先,没有任何东西迫使智能体j根据智能体k的通信消息采取行动;如果mktdoes不包含有价值的信息,j可以随意忽略它。第二,由于j的行动策略πe仅通过环境奖励进行培训,因此j只有在包含有助于j获得环境奖励的信息时,才会因观察mkt(即受mkt影响)而改变其预期行动。因此,本文假设有影响力的沟通必须为听者提供有用的信息。
实验二:有影响力的沟通
图4显示了培训智能体使用显式沟通渠道时获得的集体奖励。在这里,烧蚀模型的结构与图3相同,但通信策略πm仅在环境奖励的情况下进行训练。本文观察到,被激励通过社会影响奖励进行沟通的智能体人学习速度更快,并且在这两个游戏中的大多数训练中获得显著更高的集体奖励。事实上,在清理的情况下,本文发现,在最佳超参数设置下,α=0,这意味着以零外部奖励训练通信头最有效(见补充材料中的表2)。这表明,只有影响力才能成为培训有效沟通政策的充分机制。在《收获》中,影响力再次成为让智能体人学习协调政策并获得高回报的关键。
为了分析智能体学会的沟通行为,本文引入了三个指标,部分灵感来自(Bogin等人,2018)。说话人一致性是一个标准化的分数∈[0,1]评估p(ak|mk)的熵在第1244.4节中,当一个特定的符号被赋予时,它是如何持续地发出动作的(反之亦然)。例如,如果说话者在清洗河流时总是发出相同的符号,本文预计这个指标会很高。本文还介绍了两种即时协调(IC)的度量,它们都是互信息(MI)的度量:(1)符号\动作IC=I(mkt;ajt+1)度量影响者\说话者的符号和影响者\听者的下一个动作之间的MI,(2)action\/actionIC=I(akt;ajt+1)测量影响者的行为和受影响者的下一个行为之间的MI。为了计算这些度量,本文首先对所有轨迹步骤进行平均,然后取任意两个智能体之间的最大值,以确定是否有任何一对智能体在协调。注意,这些措施都是瞬时的,因为它们只考虑了两个连续的时间步长的短期依赖关系,并且如果一个智能体通信有影响的组成消息,即需要连续几个符号发送的信息,并且仅影响其他智能体行为,则不能捕获。

图4:具有沟通渠道的深度智能体的总集体奖励。再一次,影响力奖励对于提高或实现任何学习都至关重要。

图5:描述所学通信协议质量的指标。通过影响力奖励训练的模型表现出更一致的沟通和更多的协调,尤其是在影响力较高的时刻。
图5显示了结果。说话人一致性指标显示,影响主体比基线主体更明确地传达自己的行为,表明紧急沟通更有意义。IC指标表明,基线智能体几乎没有表现出与沟通协调行为的迹象,即说话者一致地说A,听众一致地说B。这一结果与理论结果一致廉价谈话文献的研究成果(克劳福德和索贝尔,1982年),以及MA的最新实证结果(例如Foerster等人(2016年);Lazaridou等人(2018年);曹等人(2018年)。
相比之下,本文确实看到影响因素之间存在较高的IC,但只有当本文将分析限制在影响大于或等于平均影响的时间步时(参见图5中的影响时刻)。检查结果揭示了一个共同的模式:影响在时间上是稀疏的。在不到10%的时间步长内,智能体人的影响力仅大于其平均影响力。由于听者智能体不必听任何给定的说话者,因此听者只有在说话者有益的时候才有选择地听,并且影响不可能一直发生。只有当听者决定根据说话者的信息改变其行为时,影响才会发生,在这些时刻,本文观察到高I(mkt;ajt+1)。似乎影响者已经学会了一种策略,即交流关于自己行为的有意义信息,并在相关程度足以让听者采取行动时获得影响力
通过研究沟通对智能体人的影响程度与他们获得的回报之间的关系,可以得出一个令人信服的结果:受影响最大的智能体人也会获得更高的个人环境回报。本文在这两个游戏中抽取了100种不同的实验条件(即超参数和随机种子),并对影响和个人奖励进行了归一化和关联。本文发现,更经常受到影响的智能体人在清理和收获两个方面都倾向于获得更高的任务回报,ρ=0.67,p<0.001,ρ=0.34,p<0.001。这支持了这样一个假设,即为了通过通信影响另一个智能体,通信消息应该包含帮助听者最大化自身环境回报的信息。由于更好的听众\/影响者在任务奖励方面更成功,本文有证据表明有用的信息被传递给了他们。
这一结果是有希望的,但可能取决于这里采用的具体实验方法,在这种方法中,主体之间会反复相互作用。在这种情况下,说话者传达不可靠的信息(如撒谎)对说话者没有好处,因为随着时间的推移,它会失去对听者的影响。这在一次性互动中可能无法保证。然而,考虑到重复的互动,上述结果提供了经验证据,表明作为内在动机的社会影响允许智能体人在不可能的情况下学习有意义的沟通协议。
为其他智能体建模
计算第4节中介绍的因果影响奖励需要知道在给定反事实的情况下另一个智能体的行为的概率,本文之前通过使用集中培训方法解决了这个问题,在这种方法中,智能体可以访问其他智能体的策略网络。虽然使用集中培训框架在MA中很常见(例如Foersteretal.(2017;2016)),但与每个智能体都接受独立培训的场景相比,它不太现实。本文可以放松这一假设,通过为每个智能体配备自己的其他智能体内部模型(MOA),实现独立培训。MOA由第二组完全连接的LSTM层组成,这些层连接到智能体的卷积层(见图6),并经过训练,以预测所有其他智能体的下一个动作,给出他们以前的动作,以及智能体的自我中心状态视图:p(at+1|at,skt)。MOA通过观察到的动作轨迹和交叉熵损失进行训练。

图6:MotorofOther智能体s(MOA)体系结构学习策略πe,以及预测其他智能体行为的监督模型。监督模型用于内部计算影响报酬。
训练有素的MOA可以通过以下方式计算社会影响力奖励。每个智能体都可以“想象”在每个时间步可能采取的反事实行动,并使用其内部MOA预测对其他智能体的影响。然后,它可以为自己采取据其估计最具影响力的行动提供奖励。这有一种直观的吸引力,因为它类似于人类如何推理自己对他人的影响(Ferguson等人,2010)。本文经常会问这样的反事实问题:“如果我在那种情况下做了其他事情,她会怎么做?”,
我学习p(ajt+1|akt,skt)模型需要隐式地建模其他智能体的内部状态和行为,以及环境转换函数。如果模型不准确,这将导致对因果影响回报的噪声估计。为了弥补这一点,本文只在试图影响的智能体(j)在其视野范围内时,才会给智能体(k)影响奖励,因为当k可以看到j时,p(ajt+1|akt,skt)的估计更准确。2这种约束可能会产生副作用,鼓励智能体保持更近的距离。然而,考虑到人类寻求归属感并花时间接近其他人,鼓励接近的内在社会回报是合理的(托马塞洛,们用他人的内在模型来回答这个问题。
实验三:对其他智能体进行建模
与之前一样,本文允许每个智能体的策略LSTM以上一个时间步中其他智能体的操作为条件(操作可见)。本文将其与图6所示的结构的烧蚀版本进行比较,图6不使用MOA的输出来计算奖励;相反,MOA可以被认为是一个无监督的辅助任务,可以帮助模型学习更好的共享嵌入层,鼓励它编码与预测其他智能体行为相关的信息。图7显示了使用MOA模块培训的特工获得的集体奖励。虽然本文看到辅助任务确实有助于改善A3C基线的奖励,但影响因素始终获得更高的集体奖励。这些结果表明,使用内部MOA可以有效地计算影响报酬,因此,智能体可以进行社会性但独立的学习,在没有集中控制器的情况下优化社会报酬。

图7:MOA模型的总集体奖励。同样,内在影响持续改善学习,强大的A3C智能体基线无法学习。
在这些环境中,具有影响力的智能体人获得的集体报酬高于之前的最先进水平(275份用于清理,750份用于收获)(Hughes等人,2018年)。这是令人信服的,因为之前的工作依赖于智能体可以查看彼此奖励的假设;本文不做这样的假设,而只是依靠智能体人来观察彼此的行为。补充材料的表4给出了之前工作中获得的最终集体奖励,以及所有三个实验的每个影响模型
- 发表于 2024-01-22 19:19
- 阅读 ( 2098 )
- 分类:群智能体分布式学习
