论文分享——小样本类增量学习开山之作
论文链接:https://arxiv.org/abs/2004.10956
发表会议:CVPR 2020
Few-Shot Class-Incremenal Learning
1摘要
近年来,很多研究都关注类别增量学习,在不断增加的数据类别中学习一个增量模型。但是,大多数的类增量学习方法都假设增量类中有足够的有标记训练样本。本文关注一个更具有挑战性但非常实用得场景——小样本类增量学习(FSCIL),要求模型能够从很少的标记样本中逐步学习新的类,而不会忘记旧类别。为了解决这个问题,本文提出使用神经气体网络对样本进行表征,并在此基础上提出了一个拓扑保持知识增量(TOPIC)框架。
2引言
在实际应用中,我们在大规模图像数据集上训练CNN模型,然后将其部署在终端设备上。由于终端设备经常暴露在一个动态环境中,因此迫切需要不断调整模型以识别新出现的类别。例如,智能相册排版软件可以识别用户的照片,对照片进行设计排版,制作出有着精美排版的相册。通常需要在预定义类得训练集上进行训练,在base classes上预训练过的分类器需要不断地学习new classes从而适应用户新的照片,对于新类别,大多数用户只愿意提供少量的标记样本,因此能在从很少的训练样本中逐步学习新的类别是至关重要的。本文将这种能力定义为小样本类增量学习(FSCIL)。
在FSCIL中,通常需要满足以下三个条件:(1)只训练一个分类器,也就是说整个过程中都使用一个分类器,在新的数据类别到来时,增加最后一层输出的维度来支撑模型可以识别更多的数据类别;(2)在新类别数据上训练时,旧类训练集不可见,也就是说在新的任务上我们无法访问到之前训练过的旧类数据;(3)不断到来的新类样本量是很少的。
主要的研究挑战:(1)由于旧类数据完全不可见,直接在新的数据类别上进行微调模型会造成旧类数据的灾难性遗忘;(2)新类样本量很少,模型容易对新类过拟合,在大量的测试样本上失去泛化能力。
本文贡献:
- 首次定义了小样本类增量学习的问题设置,和普通的CIL相比,FSCIL更具有挑战性。
- 提出了一个FSCIL框架TOPIC,该框架使用神经气体(NG)网络来学习用于知识表示的特征空间拓扑。TOPIC稳定了神经网络的拓扑结构以减轻遗忘,并使神经网络适应于增强对少量新类别的学习特征的判别能力。
3问题定义
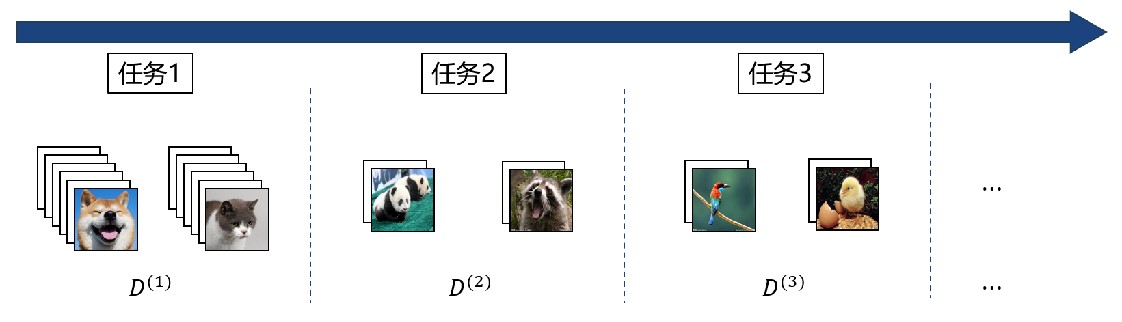
- 标记数据流{D^(1),D^(2),D^(3),⋯},L^(t)是t时刻训练样本的类别集合,L^(i)∩L^(j)=∅,i≠j
- t=1,大规模基类样本; t>1,小规模新类样本;C-way K-shot,每次引入类别数和样本数
- t时刻只可见D^(t),对于旧类样本不存储样例集
- 模型需要在当前时刻识别所有已见过的数据类别,并在这些数据类别上进行测试
4研究方法
4.1NG网络中的知识表征
在FSCIL中,严重的类别不平衡。分类器输出往往会偏置到样本量多的类别,现有方法例如知识蒸馏面临在新旧类别之间进行性能折衷的困境。与此同时,极少样本情况下,需要增大学习率以及增强新类损失的梯度,对旧类知识的维持更加困难。为此,本文尝试从一种新的认知启发的角度来解决小样本类增量学习问题。近期的认知学研究表明,物体的拓扑对维持已学知识的记忆非常重要,一旦记忆的拓扑特性发生改变,会导致人类很难认出已见过的物体,这直接导致了灾难性遗忘的产生。所以,保持住旧知识空间的拓扑结构,是解决灾难性遗忘的关键。
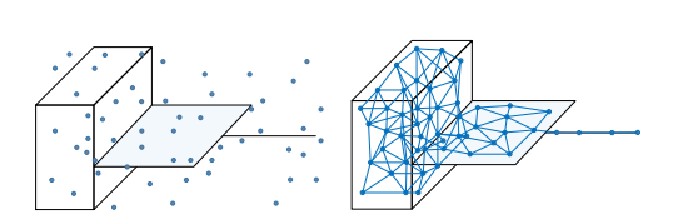
- NG网络被定义为一个无向图——G=<V,E>。
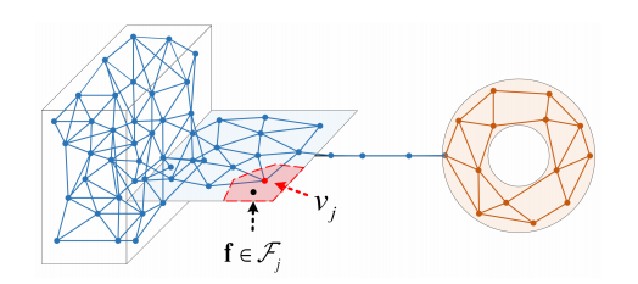
- v_j∈G=(m_j,Λ_j,z_j,c_j),m_j定义为质心向量,描述v_j在特征空间中的位置,Λ_j存储m_j各维的方差,z_j和c_j是分配的图像和标签。e_ij存储各个节点之间的拓扑连接。
- NG网络的输入为每个样本经过特征提取后的特征值。
- 计算欧式距离,排序,距离最近的节点为获胜节点接近输入值
NG网络的训练过程可以理解为节点的匹配过程,当输入一个特征值f时,首先会计算f与各个节点之间的欧式距离,然后进行排序,距离最短的节点称作获胜节点,然后根据下面的公式更新节点的质心向量和边,具体实现了获胜节点的距离会更接近当前输入样本,而邻近节点的权重也会受到一定程度的更新。这样,网络逐渐调整自身的结构以适应数据的拓扑关系。
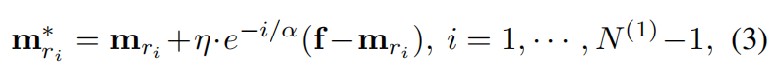
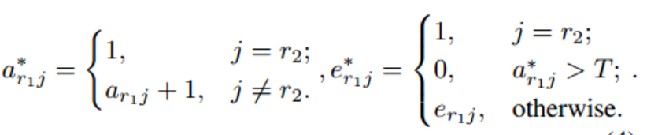
4.2Less-Forgetting Neural Gas Stabilization
通过Anchor loss损失函数,稳定网络的拓扑结构,缓解旧类的灾难性遗忘。
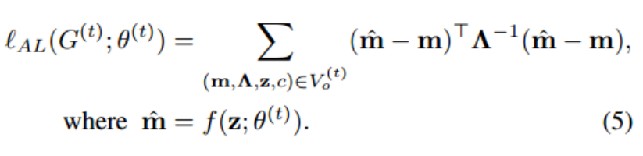
- 提取旧任务的子图G_o^(t),稳定G_o^(t)以避免遗忘旧知识
- 约束节点新的质心向量尽量接近原位置
- 方差较大的维度可以编码新旧类共享的语义信息,严格的约束阻碍知识正向转移,带来不理想的交换,使用Λ^−1衡量每个维度的重要性,放松高方差维度的限制
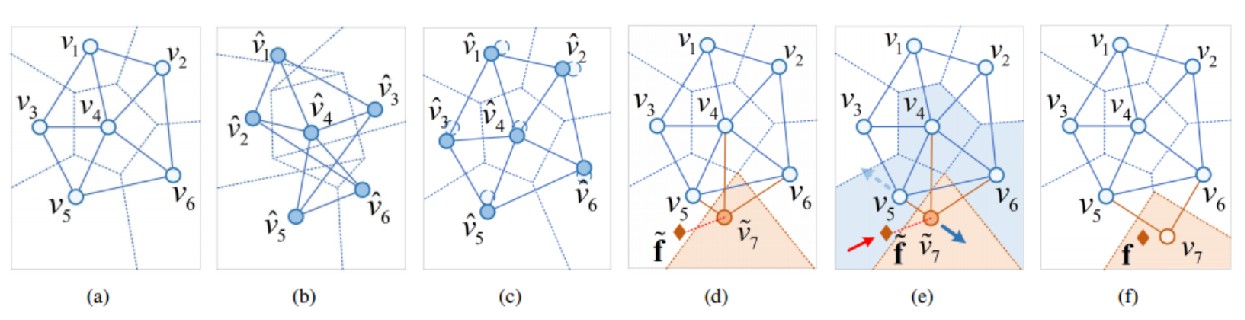
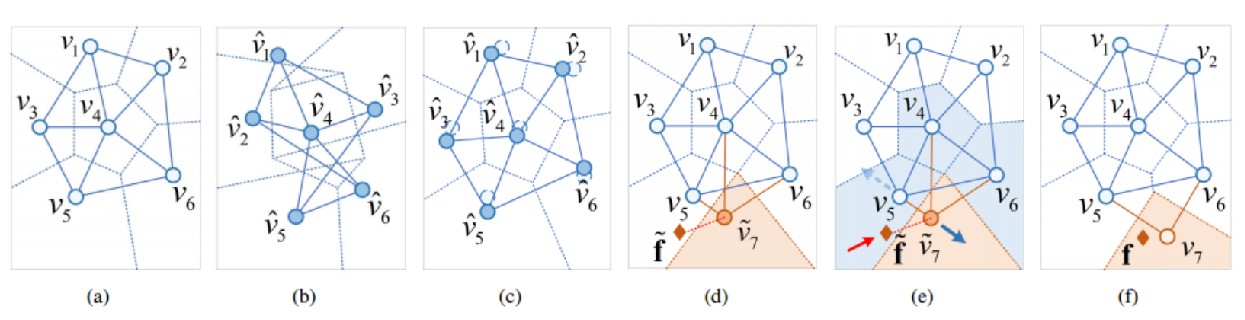
如下图所示,图b是不加约束的更新结果,图c是约束之后的更新结果,可以看到图b的拓扑结构变化很大,这样会影响对于之前旧类的识别结果,加了约束之后,拓扑图显然稳定了许多。
4.3Less-Forgetting Neural Gas Stabilization
通过Min-Max loss损失函数,让网络更好地适应新数据,缓解过拟合。
- 具有标签y的测试样本可能激活具有不同标签的邻居节点,导致该测试样本被错误分类,尤其是当获胜节点和邻居节点距离较近时,错误分类的概率就会更高。
- Min使得d(f,m_j)变小;Max使得d(m_i,m_j)变大
- 新的特征向量与正确的类别结点距离越近越好,与其他类别结点的距离越远越好
如下图所示,对应的就是减少f和v7之间的距离,增大v5和v7的距离,这样就能更好地对输入样本进行分类。
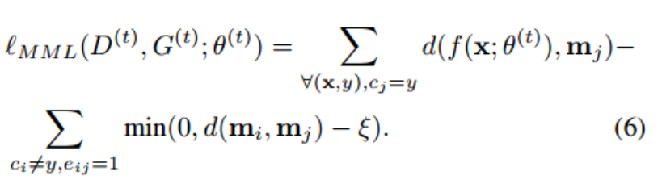
5总结与思考
- 本文提出小样本类增量学习(FSCIL)问题,其中模型需要从少量训练样本中学习新的数据类别。
- 提出了一个受脑认知科学启发的基于神经气体网络的小样本类增量学习框架TOPIC。
- 通过全面的实验结果表明,在CIFAR100,miniImageNet和CUB200数据集上,所提出的TOPIC方法明显优于其他最新的类增量学习方法。
首次定义了FSCIL的问题设置,在这篇文章之后许多研究开始关注小样本类增量学习,带来的性能增益超过了这篇文章,但是都会将这篇文章的方法作为baseline进行对比。
- 发表于 2024-01-23 10:20
- 阅读 ( 4252 )
