论文分享——联邦原型学习
论文链接:https://ieeexplore.ieee.org/abstract/document/10203389
发表会议:CVPR 2023
Rethinking Federated Learning with Domain Shift: A Prototype View
1 摘要
当联邦学习遇到域偏移,即分布式数据来自不同的域时,全局模型可能会偏向于占主导地位的域,在全局数据上的功能退化。这篇文章将联邦学习和原型学习结合起来,提出了用于域偏移下的联邦原型学习(FPL)。具体来说,构建了一个聚类原型和无偏原型,来解决域偏移下数据异构性导致的模型退化问题。
2 引言
联邦学习中有一个固有的挑战就是数据异构性,私有数据来自不同的本地客户端,具有不同的偏好,往往呈现noniid的分布。每个客户端最小化自己的本地经验风险,与全局目标发生了偏差。因此,全局模型面临着收敛速度变慢以及性能提升有限的问题。
有部分工作主要致力于引入全局信号来调节私有模型,比如最小化全局模型和本地模型的差异、限制本地模型的更新方向等等,这些方法专注于标签偏移,分布式数据还是来自同一域的,通过不平衡采样模拟数据异质性,普遍的方法是采用狄利克雷策略生成不同的标签分布,并没有关注域偏移的问题。如下图所示,私有模型过渡拟合本地域的分布,无法为其他域提供分类能力。全局信息不足以描述各种领域的知识,从而阻碍了模型泛化能力的提升。那如果为域相似的客户端保留一个模型,不同的域保留多个模型来提取各自领域的知识,这样可能会导致通信和计算成本的提高。
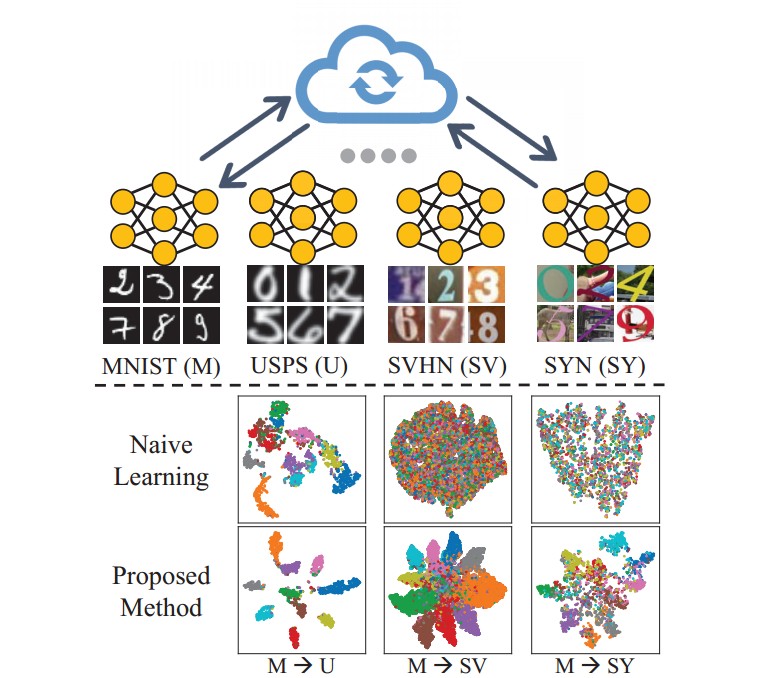 考虑到精度和效率两方面,这篇文章在联邦学习中引入原型学习,这里先讲到这里,方法部分再继续说如何使用原型学习来解决文章背景下所面临的问题,直接说具体的组件有点跳跃。
考虑到精度和效率两方面,这篇文章在联邦学习中引入原型学习,这里先讲到这里,方法部分再继续说如何使用原型学习来解决文章背景下所面临的问题,直接说具体的组件有点跳跃。
3 研究方法
3.1 问题驱动motivation
原型学习就是为每个类别训练一个原型,由属于同一类别的特征均值计算得到:
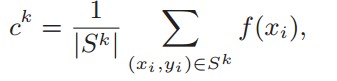 在联邦学习中,进一步定义来自第m个参与者的第k类原型:
在联邦学习中,进一步定义来自第m个参与者的第k类原型:
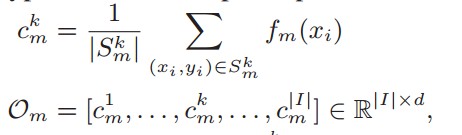 如果将原型学习引入联邦学习的框架下,首先想到的一个简单的方法就是像FedAvg一样,对于来自不同参与方的每个类别的原型取均值,构建一个全局原型,全局原型可以表述为:
如果将原型学习引入联邦学习的框架下,首先想到的一个简单的方法就是像FedAvg一样,对于来自不同参与方的每个类别的原型取均值,构建一个全局原型,全局原型可以表述为:
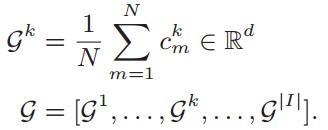 像全局模型一样,全局模型会遇到两个主要的问题:
像全局模型一样,全局模型会遇到两个主要的问题:
问题1:只通过一个原型来描述每个类别的语义信息,在域偏移下的联邦学习中无法描述出不同域的特征,也就是缺少泛化性。
问题2:联邦学习参与者数据分布未知,全局原型可能会偏向于占主导地位(数据量庞大的参与者)的参与方的数据分布,导致最终优化目标的偏移。
ok,问题动机描述清楚了,下面开始提出本文的思想!!!!
分界线####################################################################################################################
3.2 聚类原型
与全局原型相比,我们通过无监督聚类方法FINCH选择了具有代表性的原型,而不是为每个类别只保留单个原型。来自不同域的原型可能无法合并在一起,而来自相似域的原型则属于同一组,利用余弦相似度来评估两个原型之间的距离,并将距离最小的两个原型视为邻居原型,分在同一集合中。定义第k个类别原型的邻接矩阵:
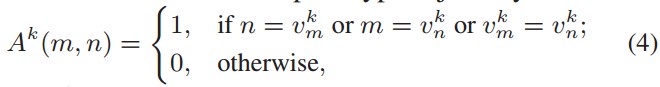 vmk指的是参与者m关于类别k的原型的最近的邻居,如果m和n是彼此最近的邻居或者他俩拥有相同的最近的邻居,就定义矩阵的值为1,分为同一类。根据公式4的聚类结果,选择J个具有代表性的原型作为聚类原型:
vmk指的是参与者m关于类别k的原型的最近的邻居,如果m和n是彼此最近的邻居或者他俩拥有相同的最近的邻居,就定义矩阵的值为1,分为同一类。根据公式4的聚类结果,选择J个具有代表性的原型作为聚类原型:
 问题1得到解决。
问题1得到解决。
3.3 无偏原型
聚类原型通常是不稳定的,无监督聚类方法每轮都会生成不同的聚类原型,无法确保一个稳定并且公平的收敛点,进一步对聚类原型进行平均处理,得到无偏原型:
 无偏原型很大程度避免了模型偏向于主导者。
无偏原型很大程度避免了模型偏向于主导者。
问题2得到解决。
3.4 讨论
为了更深一步的理解,文章在下图中解释了这三种类型的原型的区别:
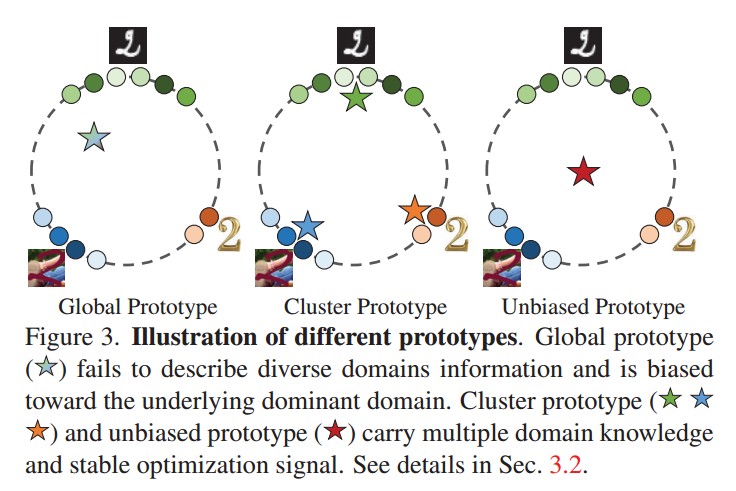 从上图可以看出,全局原型固有地呈现出有限的知识,在异构联邦学习中偏向于潜在的主导地位的域。聚类原型和无偏原型相互补充解决了这个问题。聚类原型提供了丰富的不同的域知识,无偏原型代表了一个较为理想的优化目标,共同确保了泛化性和稳定性。原型的尺寸是大大小于模型参数的,确保了较少的计算成本,同时聚类原型和无偏原型经过了两三次的平均操作,也确保了隐私性。
从上图可以看出,全局原型固有地呈现出有限的知识,在异构联邦学习中偏向于潜在的主导地位的域。聚类原型和无偏原型相互补充解决了这个问题。聚类原型提供了丰富的不同的域知识,无偏原型代表了一个较为理想的优化目标,共同确保了泛化性和稳定性。原型的尺寸是大大小于模型参数的,确保了较少的计算成本,同时聚类原型和无偏原型经过了两三次的平均操作,也确保了隐私性。
介绍完了这两种原型,文章基本的思想已经大致介绍完毕了,然后就是将这两种原型应用到联邦学习中,整体并不是很复杂。
3.5 联邦原型学习
先上架构图:
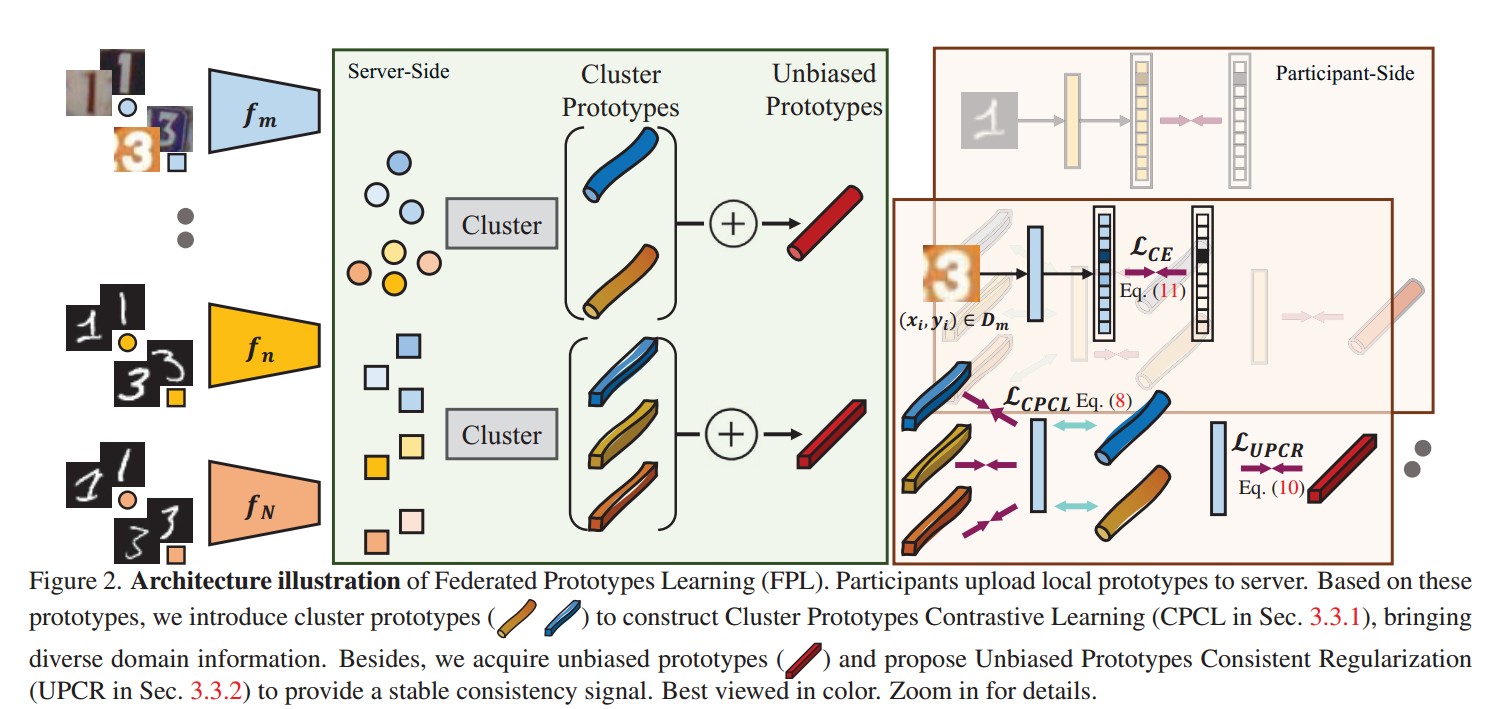 主要有两个关键的模块聚类原型对比学习(CPCL)和无偏原型正则化(UPCR)。
主要有两个关键的模块聚类原型对比学习(CPCL)和无偏原型正则化(UPCR)。
3.5.1聚类原型对比学习
一个具有良好泛化表征的特征向量不仅应该是有区别性的,以为不同类别提供清晰的决策边界,而且应该尽可能对不同领域的扭曲保持不变。定义实例样本嵌入zi与相应聚类原型的相似度:
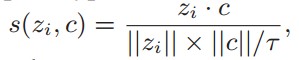 其中,温度超参数τ控制表示的集中度,期望增加与语义一致的聚类原型的相似性,而不同聚类原型的相似性较小。经过推到,可以得到以下:
其中,温度超参数τ控制表示的集中度,期望增加与语义一致的聚类原型的相似性,而不同聚类原型的相似性较小。经过推到,可以得到以下:
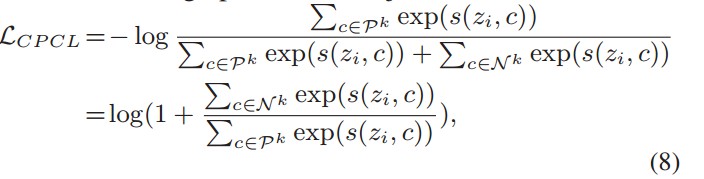
 最小化LCPCL等价于嵌入向量zi紧密拉向其分配的正聚类原型(Pk),并将zi远离其他负原型(N k)。这不仅旨在对不同领域的扭曲保持不变,还增强了语义的传播属性,确保了特征空间的泛化和区分性,
最小化LCPCL等价于嵌入向量zi紧密拉向其分配的正聚类原型(Pk),并将zi远离其他负原型(N k)。这不仅旨在对不同领域的扭曲保持不变,还增强了语义的传播属性,确保了特征空间的泛化和区分性,
3.5.2 无偏原型正则化
尽管聚类原型在处理域偏移时能够提供多样化的域知识,但由于聚类原型是在每次通信中动态生成的,并且由于无监督聚类方法,其规模在变化。因此,聚类原型无法在不同的通信时期提供稳定的收敛方向。通过无偏原型正则化确保稳定性:
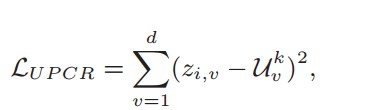
3.5.3 整体流程
伪代码如下:
 在每个通信时期,服务器将聚类原型和无偏原型分发给参与者。在本地更新中,每个参与者在本地数据上进行优化,而优化目标由式(12)定义, LCE是交叉熵损失。
在每个通信时期,服务器将聚类原型和无偏原型分发给参与者。在本地更新中,每个参与者在本地数据上进行优化,而优化目标由式(12)定义, LCE是交叉熵损失。
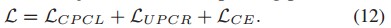
4 实验
数据集:
为Digits和Office Caltech任务初始化了20和10个参与者,并随机分配了域给参与者。具体来说,Digits任务是MNIST:3,USPS:7,SVHN:6和SYN:4。Office Caltech是Caltech:3,Amazon:2,Webcam:1和DSLR:4。
对照方法:FedAvg(AISTATS’17),FedProx(arXiv’18),MOON(CVPR’21),FedDyn(ICLR’21),FedOPT(ICLR’21),FedProc(arXiv’21)和FedProto(AAAI’22)(使用参数平均)。
结果大家可以自己看看,作者还针对不同模块做了消融实验,好累啊懒得贴了。/////////
5 总结
方法思想其实还是挺简单的,作者的思路也是很值得我们学习的,感觉这篇文章的参考价值还是很大的,因为原型学习在小样本问题上表现得也挺好,之后打算复现一下这篇文章。
- 发表于 2024-02-27 11:52
- 阅读 ( 4669 )
